- Added package.json to manage development scripts. - Updated restart-services.ps1 to call the new dev script for starting services. - Refactored start-admin.ps1, start-backend.ps1, start-frontend.ps1, and start-mcp.ps1 to utilize the dev script for starting respective services. - Enhanced stop-services.ps1 to improve process termination logic by matching command patterns.
570 lines
18 KiB
Markdown
570 lines
18 KiB
Markdown
---
|
||
title: "mysql个人常用命令及操作"
|
||
description:
|
||
date: 2021-09-21T16:13:24+08:00
|
||
draft: true
|
||
slug: mysql
|
||
image:
|
||
categories:
|
||
- Database
|
||
tags:
|
||
- Linux
|
||
- Mysql
|
||
- Sql
|
||
---
|
||
|
||
启动`mysql`
|
||
|
||
```bash
|
||
sudo service mysql start
|
||
```
|
||
|
||
使用`root`账户登录`mysql`
|
||
|
||
```bash
|
||
sudo mysql -u root
|
||
```
|
||
|
||
查看数据库信息
|
||
|
||
```mysql
|
||
show databases;
|
||
```
|
||
|
||
新增数据库
|
||
|
||
```mysql
|
||
create database <新增的数据库名>;
|
||
# 示例,新增一个名为gradesystem的数据库
|
||
create database gradesystem;
|
||
|
||
```
|
||
|
||
切换数据库
|
||
|
||
```mysql
|
||
use <切换的数据库名>;
|
||
# 示例,切换至gradesystem数据库
|
||
use gradesystem;
|
||
```
|
||
|
||
查看数据库中的表
|
||
|
||
```mysql
|
||
# 查看数据库中所有的表
|
||
show tables;
|
||
```
|
||
|
||
新增表
|
||
|
||
```mysql
|
||
# MySQL不区分大小写
|
||
CREATE TABLE student(
|
||
sid int NOT NULL AUTO_INCREMENT,
|
||
sname varchar(20) NOT NULL,
|
||
gender varchar(10) NOT NULL,
|
||
PRIMARY KEY(sid)
|
||
);
|
||
# 新增一个表名为学生的表。
|
||
# AUTO_INCREMENT, 自动地创建主键字段的值。
|
||
# PRIMARY KEY(sid) 设置主键为sid
|
||
CREATE TABLE course(
|
||
cid int not null auto_increment,
|
||
cname varchar(20) not null,
|
||
primary key(cid)
|
||
);
|
||
# 新增一个表名为课程的表。
|
||
# primary key(cid) 设置主键为cid
|
||
|
||
CREATE TABLE mark(
|
||
mid int not null auto_increment,
|
||
sid int not null,
|
||
cid int not null,
|
||
score int not null,
|
||
primary key(mid),
|
||
foreign key(sid) references student(sid),
|
||
foreign key(cid) references course(cid)
|
||
);
|
||
# 新增一个表明为mark的表
|
||
# primary key(cid) 设置主键为cid
|
||
# foreign 设置外键为sid
|
||
# foreign 设置外键为cid
|
||
|
||
insert into student values(1,'Tom','male'),(2,'Jack','male'),(3,'Rose','female');
|
||
# 向student表插入数据,sid为1,sname为'Tom',gender为'male'
|
||
|
||
insert into course values(1,'math'),(2,'physics'),(3,'chemistry');
|
||
# 向course表插入数据,sid为1,cname为'math'
|
||
|
||
insert into mark values(1,1,1,80);
|
||
# 向mark表插入数据,mid为1,sid为1,cid为1,score为80
|
||
```
|
||
|
||
### 向数据库插入数据
|
||
|
||
```mysql
|
||
source <数据库文件所在目录>
|
||
|
||
|
||
```
|
||
|
||
## SELECT语句查询
|
||
|
||
SELECT 语句的基本格式为:
|
||
|
||
```bash
|
||
SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
|
||
```
|
||
|
||
```mysql
|
||
select name,age from employee;
|
||
# 查看employee的name列和age列
|
||
|
||
select name,age from employee where age > 25;
|
||
# 筛选出age 大于25的结果
|
||
|
||
select name,age,phone from employee where name = 'Mary';
|
||
# 筛选出name为'Mary'的name,age,phone
|
||
|
||
select name,age,phone from employee where age < 25 or age >30;
|
||
# 筛选出age小于30或大于25的name,age,phone
|
||
|
||
select name,age,phone from employee where age > 25 and age < 30;
|
||
# 筛选出age大于25且小于30的name,age,phone
|
||
|
||
select name,age,phone from employee where age between 25 and 30;
|
||
# 筛选出包含25和30的,name,age,phone
|
||
|
||
select name,age,phone,in_dpt from employee where in_dpt in('dpt3','dpt4');
|
||
# 筛选出在dpt3或dpt4里面的name,age,phone,in_dpt
|
||
|
||
select name,age,phone,in_dpt from employee where in_dpt not in('dpt1','dpt3');
|
||
# 筛选出不在dpt1和dpt3的name,age,phone,in_dpt
|
||
|
||
|
||
```
|
||
|
||
## 通配符
|
||
|
||
关键字 **LIKE** 可用于实现模糊查询,常见于搜索功能中。
|
||
|
||
和 LIKE 联用的通常还有通配符,代表未知字符。SQL 中的通配符是 `_` 和 `%` 。其中 `_` 代表一个**未指定**字符,`%` 代表**不定个**未指定字符
|
||
|
||
```mysql
|
||
select name,age,phone from employee where phone like '1101__';
|
||
# 筛选出1101开头的六位数字的name,age,phone
|
||
|
||
select name,age,phone from employee where name like 'J%';
|
||
# 筛选出name位J开头的人的name,age,phone
|
||
```
|
||
|
||
## 排序
|
||
|
||
为了使查询结果看起来更顺眼,我们可能需要对结果按某一列来排序,这就要用到 **ORDER BY** 排序关键词。默认情况下,**ORDER BY** 的结果是**升序**排列,而使用关键词 **ASC** 和 **DESC** 可指定**升序**或**降序**排序。 比如,我们**按 salary 降序排列**,SQL 语句为
|
||
|
||
```mysql
|
||
select name,age,salary,phone from employee order by salary desc;
|
||
# salary列按降序排列
|
||
select name,age,salary,phone from employee order by salary;
|
||
# 不加 DESC 或 ASC 将默认按照升序排列。
|
||
```
|
||
|
||
## SQL 内置函数和计算
|
||
|
||
置函数,这些函数都对 SELECT 的结果做操作:
|
||
|
||
| 函数名: | COUNT | SUM | AVG | MAX | MIN |
|
||
| -------- | ----- | ---- | -------- | ------ | ------ |
|
||
| 作用: | 计数 | 求和 | 求平均值 | 最大值 | 最小值 |
|
||
|
||
> 其中 COUNT 函数可用于任何数据类型(因为它只是计数),而 SUM 、AVG 函数都只能对数字类数据类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
|
||
|
||
|
||
|
||
```mysql
|
||
select max(salary) as max_salary,min(salary) from employee;
|
||
# 使用as关键字可以给值重命名,
|
||
```
|
||
|
||
## 连接查询
|
||
|
||
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 **(join)** 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
|
||
|
||
```mysql
|
||
select id,name,people_num from employee,department where employee.in_dpt = department.dpt_name order by id;
|
||
# 这条语句查询出的是,各员工所在部门的人数,其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表:
|
||
|
||
select id,name,people_num from employee join department on employee.in_dpt = department.dpt_name order by id;
|
||
# 另一个连接语句格式是使用 JOIN ON 语法,刚才的语句等同于以上语句
|
||
```
|
||
|
||
## 删除数据库
|
||
|
||
```mysql
|
||
drop database test_01;
|
||
# 删除名为test_01的数据库;
|
||
```
|
||
|
||
### 修改表
|
||
|
||
重命名一张表的语句有多种形式,以下 3 种格式效果是一样的:
|
||
|
||
```sql
|
||
RENAME TABLE 原名 TO 新名字;
|
||
|
||
ALTER TABLE 原名 RENAME 新名;
|
||
|
||
ALTER TABLE 原名 RENAME TO 新名;
|
||
```
|
||
|
||
进入数据库 mysql_shiyan :
|
||
|
||
```mysql
|
||
use mysql_shiyan
|
||
```
|
||
|
||
使用命令尝试修改 `table_1` 的名字为 `table_2` :
|
||
|
||
```mysql
|
||
RENAME TABLE table_1 TO table_2;
|
||
```
|
||
|
||
删除一张表的语句,类似于刚才用过的删除数据库的语句,格式是这样的:
|
||
|
||
```sql
|
||
DROP TABLE 表名字;
|
||
```
|
||
|
||
比如我们把 `table_2` 表删除:
|
||
|
||
```mysql
|
||
DROP TABLE table_2;
|
||
```
|
||
|
||
#### 增加一列
|
||
|
||
在表中增加一列的语句格式为:
|
||
|
||
```sql
|
||
ALTER TABLE 表名字 ADD COLUMN 列名字 数据类型 约束;
|
||
或:
|
||
ALTER TABLE 表名字 ADD 列名字 数据类型 约束;
|
||
```
|
||
|
||
现在 employee 表中有 `id、name、age、salary、phone、in_dpt` 这 6 个列,我们尝试加入 `height` (身高)一个列并指定 DEFAULT 约束:
|
||
|
||
```mysql
|
||
ALTER TABLE employee ADD height INT(4) DEFAULT 170;
|
||
```
|
||
|
||
可以发现:新增加的列,被默认放置在这张表的最右边。如果要把增加的列插入在指定位置,则需要在语句的最后使用 AFTER 关键词(**“AFTER 列 1” 表示新增的列被放置在 “列 1” 的后面**)。
|
||
|
||
> 提醒:语句中的 INT(4) 不是表示整数的字节数,而是表示该值的显示宽度,如果设置填充字符为 0,则 170 显示为 0170
|
||
|
||
比如我们新增一列 `weight`(体重) 放置在 `age`(年龄) 的后面:
|
||
|
||
```mysql
|
||
ALTER TABLE employee ADD weight INT(4) DEFAULT 120 AFTER age;
|
||
```
|
||
|
||
|
||
|
||
上面的效果是把新增的列加在某位置的后面,如果想放在第一列的位置,则使用 `FIRST` 关键词,如语句:
|
||
|
||
```sql
|
||
ALTER TABLE employee ADD test INT(10) DEFAULT 11 FIRST;
|
||
```
|
||
|
||
#### 删除一列
|
||
|
||
删除表中的一列和刚才使用的新增一列的语句格式十分相似,只是把关键词 `ADD` 改为 `DROP` ,语句后面不需要有数据类型、约束或位置信息。具体语句格式:
|
||
|
||
```sql
|
||
ALTER TABLE 表名字 DROP COLUMN 列名字;
|
||
|
||
或: ALTER TABLE 表名字 DROP 列名字;
|
||
```
|
||
|
||
我们把刚才新增的 `test` 删除:
|
||
|
||
```sql
|
||
ALTER TABLE employee DROP test;
|
||
```
|
||
|
||
#### 重命名一列
|
||
|
||
这条语句其实不只可用于重命名一列,准确地说,它是对一个列做修改(CHANGE) :
|
||
|
||
```sql
|
||
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;
|
||
```
|
||
|
||
> **注意:这条重命名语句后面的 “数据类型” 不能省略,否则重命名失败。**
|
||
|
||
当**原列名**和**新列名**相同的时候,指定新的**数据类型**或**约束**,就可以用于修改数据类型或约束。需要注意的是,修改数据类型可能会导致数据丢失,所以要慎重使用。
|
||
|
||
我们用这条语句将 “height” 一列重命名为汉语拼音 “shengao” ,效果如下:
|
||
|
||
```mysql
|
||
ALTER TABLE employee CHANGE height shengao INT(4) DEFAULT 170;
|
||
```
|
||
|
||
#### 改变数据类型
|
||
|
||
要修改一列的数据类型,除了使用刚才的 **CHANGE** 语句外,还可以用这样的 **MODIFY** 语句:
|
||
|
||
```sql
|
||
ALTER TABLE 表名字 MODIFY 列名字 新数据类型;
|
||
```
|
||
|
||
再次提醒,修改数据类型必须小心,因为这可能会导致数据丢失。在尝试修改数据类型之前,请慎重考虑。
|
||
|
||
#### 修改表中某个值
|
||
|
||
大多数时候我们需要做修改的不会是整个数据库或整张表,而是表中的某一个或几个数据,这就需要我们用下面这条命令达到精确的修改:
|
||
|
||
```sql
|
||
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件;
|
||
```
|
||
|
||
比如,我们要把 Tom 的 age 改为 21,salary 改为 3000:
|
||
|
||
```mysql
|
||
UPDATE employee SET age=21,salary=3000 WHERE name='Tom';
|
||
```
|
||
|
||
> **注意:一定要有 WHERE 条件,否则会出现你不想看到的后果**
|
||
|
||
#### 删除一行记录
|
||
|
||
删除表中的一行数据,也必须加上 WHERE 条件,否则整列的数据都会被删除。删除语句:
|
||
|
||
```sql
|
||
DELETE FROM 表名字 WHERE 条件;
|
||
```
|
||
|
||
我们尝试把 Tom 的数据删除:
|
||
|
||
```mysql
|
||
DELETE FROM employee WHERE name='Tom';
|
||
```
|
||
|
||
#### 索引
|
||
|
||
索引是一种与表有关的结构,它的作用相当于书的目录,可以根据目录中的页码快速找到所需的内容。
|
||
|
||
当表中有大量记录时,若要对表进行查询,没有索引的情况是全表搜索:将所有记录一一取出,和查询条件进行对比,然后返回满足条件的记录。这样做会执行大量磁盘 I/O 操作,并花费大量数据库系统时间。
|
||
|
||
而如果在表中已建立索引,在索引中找到符合查询条件的索引值,通过索引值就可以快速找到表中的数据,可以**大大加快查询速度**。
|
||
|
||
对一张表中的某个列建立索引,有以下两种语句格式:
|
||
|
||
```sql
|
||
ALTER TABLE 表名字 ADD INDEX 索引名 (列名);
|
||
|
||
CREATE INDEX 索引名 ON 表名字 (列名);
|
||
```
|
||
|
||
我们用这两种语句分别建立索引:
|
||
|
||
```sql
|
||
ALTER TABLE employee ADD INDEX idx_id (id); #在employee表的id列上建立名为idx_id的索引
|
||
|
||
CREATE INDEX idx_name ON employee (name); #在employee表的name列上建立名为idx_name的索引
|
||
```
|
||
|
||
索引的效果是加快查询速度,当表中数据不够多的时候是感受不出它的效果的。这里我们使用命令 **SHOW INDEX FROM 表名字;** 查看刚才新建的索引:
|
||
|
||
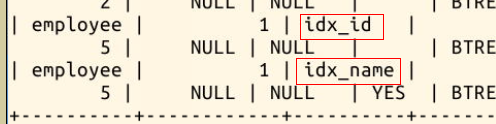
|
||
|
||
在使用 SELECT 语句查询的时候,语句中 WHERE 里面的条件,会**自动判断有没有可用的索引**。
|
||
|
||
比如有一个用户表,它拥有用户名(username)和个人签名(note)两个字段。其中用户名具有唯一性,并且格式具有较强的限制,我们给用户名加上一个唯一索引;个性签名格式多变,而且允许不同用户使用重复的签名,不加任何索引。
|
||
|
||
这时候,如果你要查找某一用户,使用语句 `select * from user where username=?` 和 `select * from user where note=?` 性能是有很大差距的,对**建立了索引的用户名**进行条件查询会比**没有索引的个性签名**条件查询快几倍,在数据量大的时候,这个差距只会更大。
|
||
|
||
一些字段不适合创建索引,比如性别,这个字段存在大量的重复记录无法享受索引带来的速度加成,甚至会拖累数据库,导致数据冗余和额外的 CPU 开销。
|
||
|
||
## 视图
|
||
|
||
|
||
|
||
视图是从一个或多个表中导出来的表,是一种**虚拟存在的表**。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据。
|
||
|
||
注意理解视图是虚拟的表:
|
||
|
||
- 数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
|
||
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
|
||
- 视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
|
||
- 在使用视图的时候,可以把它当作一张表。
|
||
|
||
创建视图的语句格式为:
|
||
|
||
```sql
|
||
CREATE VIEW 视图名(列a,列b,列c) AS SELECT 列1,列2,列3 FROM 表名字;
|
||
```
|
||
|
||
可见创建视图的语句,后半句是一个 SELECT 查询语句,所以**视图也可以建立在多张表上**,只需在 SELECT 语句中使用**子查询**或**连接查询**,这些在之前的实验已经进行过。
|
||
|
||
现在我们创建一个简单的视图,名为 **v_emp**,包含**v_name**,**v_age**,**v_phone**三个列:
|
||
|
||
```sql
|
||
CREATE VIEW v_emp (v_name,v_age,v_phone) AS SELECT name,age,phone FROM employee;
|
||
```
|
||
|
||

|
||
|
||
## 导出
|
||
|
||
|
||
|
||
导出与导入是相反的过程,是把数据库某个表中的数据保存到一个文件之中。导出语句基本格式为:
|
||
|
||
```sql
|
||
SELECT 列1,列2 INTO OUTFILE '文件路径和文件名' FROM 表名字;
|
||
```
|
||
|
||
**注意:语句中 “文件路径” 之下不能已经有同名文件。**
|
||
|
||
现在我们把整个 employee 表的数据导出到 /var/lib/mysql-files/ 目录下,导出文件命名为 **out.txt** 具体语句为:
|
||
|
||
```sql
|
||
SELECT * INTO OUTFILE '/var/lib/mysql-files/out.txt' FROM employee;
|
||
```
|
||
|
||
用 gedit 可以查看导出文件 `/var/lib/mysql-files/out.txt` 的内容:
|
||
|
||
> 也可以使用 `sudo cat /var/lib/mysql-files/out.txt` 命令查看。
|
||
|
||
## 备份
|
||
|
||
|
||
|
||
数据库中的数据十分重要,出于安全性考虑,在数据库的使用中,应该注意使用备份功能。
|
||
|
||
> 备份与导出的区别:导出的文件只是保存数据库中的数据;而备份,则是把数据库的结构,包括数据、约束、索引、视图等全部另存为一个文件。
|
||
|
||
**mysqldump** 是 MySQL 用于备份数据库的实用程序。它主要产生一个 SQL 脚本文件,其中包含从头重新创建数据库所必需的命令 CREATE TABLE INSERT 等。
|
||
|
||
使用 mysqldump 备份的语句:
|
||
|
||
```bash
|
||
mysqldump -u root 数据库名>备份文件名; #备份整个数据库
|
||
|
||
mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表
|
||
```
|
||
|
||
> mysqldump 是一个备份工具,因此该命令是在终端中执行的,而不是在 mysql 交互环境下
|
||
|
||
我们尝试备份整个数据库 `mysql_shiyan`,将备份文件命名为 `bak.sql`,先 `Ctrl+D` 退出 MySQL 控制台,再打开 Xfce 终端,在终端中输入命令:
|
||
|
||
```bash
|
||
cd /home/shiyanlou/
|
||
mysqldump -u root mysql_shiyan > bak.sql;
|
||
```
|
||
|
||
使用命令 “ls” 可见已经生成备份文件 `bak.sql`:
|
||
|
||

|
||
|
||
> 你可以用 gedit 查看备份文件的内容,可以看见里面不仅保存了数据,还有所备份的数据库的其它信息。
|
||
|
||
## 恢复
|
||
|
||
|
||
|
||
用备份文件恢复数据库,其实我们早就使用过了。在本次实验的开始,我们使用过这样一条命令:
|
||
|
||
```bash
|
||
source /tmp/SQL6/MySQL-06.sql
|
||
```
|
||
|
||
这就是一条恢复语句,它把 MySQL-06.sql 文件中保存的 `mysql_shiyan` 数据库恢复。
|
||
|
||
还有另一种方式恢复数据库,但是在这之前我们先使用命令新建一个**空的数据库 test**:
|
||
|
||
```bash
|
||
mysql -u root #因为在上一步已经退出了 MySQL,现在需要重新登录
|
||
CREATE DATABASE test; #新建一个名为test的数据库
|
||
```
|
||
|
||
再次 **Ctrl+D** 退出 MySQL,然后输入语句进行恢复,把刚才备份的 **bak.sql** 恢复到 **test** 数据库:
|
||
|
||
```bash
|
||
mysql -u root test < bak.sql
|
||
```
|
||
|
||
我们输入命令查看 test 数据库的表,便可验证是否恢复成功:
|
||
|
||
```bash
|
||
mysql -u root # 因为在上一步已经退出了 MySQL,现在需要重新登录
|
||
use test # 连接数据库 test
|
||
|
||
SHOW TABLES; # 查看 test 数据库的表
|
||
```
|
||
|
||
可以看见原数据库的 4 张表和 1 个视图,现在已经恢复到 test 数据库中:
|
||
|
||

|
||
|
||
再查看 employee 表的恢复情况:
|
||
|
||
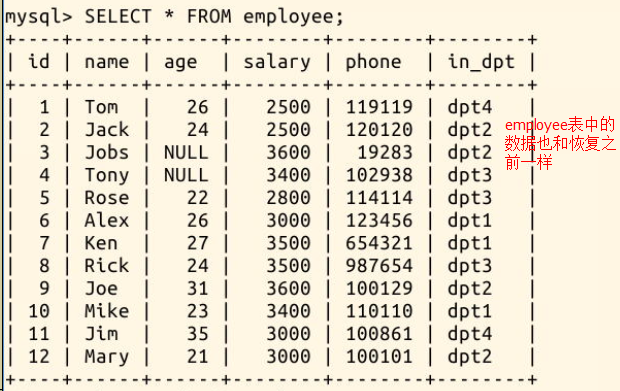
|
||
|
||
## Mysql授权
|
||
|
||
1. 登录MySQL:
|
||
|
||
```sql
|
||
mysql -u root -p
|
||
```
|
||
|
||
2. 进入MySQL并查看用户和主机:
|
||
|
||
```sql
|
||
use mysql;
|
||
select host,user from user;
|
||
```
|
||
|
||
3. 更新root用户允许远程连接:
|
||
|
||
```sql
|
||
update user set host='%' where user='root';
|
||
```
|
||
|
||
4. 设置root用户密码:
|
||
|
||
```sql
|
||
alter user 'root'@'localhost' identified by 'your_password';
|
||
```
|
||
|
||
注意:不要使用临时密码。
|
||
|
||
5. 授权允许远程访问:
|
||
|
||
```sql
|
||
grant all privileges on *.* to 'root'@'%' identified by 'password';
|
||
```
|
||
|
||
请将命令中的“password”更改为您的MySQL密码。
|
||
|
||
6. 刷新授权:
|
||
|
||
```sql
|
||
flush privileges;
|
||
```
|
||
|
||
7. 关闭授权:
|
||
|
||
```sql
|
||
revoke all on *.* from dba@localhost;
|
||
```
|
||
|
||
8. 查看MySQL初始密码:
|
||
|
||
```bash
|
||
grep "password" /var/log/mysqld.log
|
||
```
|
||
|
||
通过以上操作,您的MySQL可以被远程连接并进行管理。请注意在授权和更新用户权限时,应只授权特定的数据库或表格,而不是使用通配符,以提高安全性和减少不必要的权限。在进行远程访问授权时,应只授权特定的IP地址或IP地址段,而不是使用通配符,以减少潜在的安全威胁。同时,建议使用强密码,并定期更换密码以提高安全性。
|