feat: refresh content workflow and verification settings
All checks were successful
docker-images / build-and-push (admin, admin, termi-astro-admin, admin/Dockerfile) (push) Successful in 43s
docker-images / build-and-push (backend, backend, termi-astro-backend, backend/Dockerfile) (push) Successful in 25m9s
docker-images / build-and-push (frontend, frontend, termi-astro-frontend, frontend/Dockerfile) (push) Successful in 51s
All checks were successful
docker-images / build-and-push (admin, admin, termi-astro-admin, admin/Dockerfile) (push) Successful in 43s
docker-images / build-and-push (backend, backend, termi-astro-backend, backend/Dockerfile) (push) Successful in 25m9s
docker-images / build-and-push (frontend, frontend, termi-astro-frontend, frontend/Dockerfile) (push) Successful in 51s
This commit is contained in:
24
backend/content/posts/building-blog-with-astro.md
Normal file
24
backend/content/posts/building-blog-with-astro.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 徐霞客游记·游太和山日记(下)
|
||||
slug: building-blog-with-astro
|
||||
description: 《徐霞客游记》太和山下篇,包含琼台、南岩与五龙宫等段落。
|
||||
category: 古籍游记
|
||||
post_type: article
|
||||
pinned: false
|
||||
status: published
|
||||
visibility: public
|
||||
noindex: false
|
||||
tags:
|
||||
- 徐霞客
|
||||
- 游记
|
||||
- 太和山
|
||||
- 长文测试
|
||||
---
|
||||
|
||||
# 徐霞客游记·游太和山日记(下)
|
||||
|
||||
更衣上金顶。瞻叩毕,天宇澄朗,下瞰诸峰,近者鹄峙,远者罗列,诚天真奥区也。
|
||||
|
||||
遂从三天门之右小径下峡中。此径无级无索,乱峰离立,路穿其间,迥觉幽胜。三里馀,抵蜡烛峰右,泉涓涓溢出路旁,下为蜡烛涧。
|
||||
|
||||
从宫左趋雷公洞。洞在悬崖间。乃从北天门下,一径阴森,滴水、仙侣二岩,俱在路左,飞崖上突,泉滴沥于中。
|
||||
@@ -1,242 +0,0 @@
|
||||
---
|
||||
title: "Canokey入门指南:2FA、OpenPGP、PIV"
|
||||
description: 本文是一份Canokey入门指南,将介绍如何使用Canokey进行2FA、OpenPGP和PIV等操作。其中,2FA部分将介绍如何使用Yubikey Authenticator进行管理,OpenPGP部分将介绍如何生成GPG密钥并使用Canokey进行身份验证和加密解密,PIV部分将介绍如何在Canokey中生成PIV证书并使用其进行身份验证。
|
||||
date: 2022-08-19T16:42:40+08:00
|
||||
draft: false
|
||||
slug: canokeys
|
||||
image:
|
||||
categories:
|
||||
- Linux
|
||||
tags:
|
||||
- Linux
|
||||
---
|
||||
|
||||
|
||||
|
||||
# 2FA
|
||||
|
||||
`Canokey`使用`Yubikey Authenticator`来进行管理`2FA`。
|
||||
|
||||
下载`Yubikey Authenticator`,以下为`Yubikey Authenticator`官方下载网址
|
||||
|
||||
```http
|
||||
https://www.yubico.com/products/yubico-authenticator/#h-download-yubico-authenticator
|
||||
```
|
||||
|
||||
运行`Yubikey Authenticator`
|
||||
|
||||
进入`custom reader`,在`Custom reader fiter`处填入 `CanoKey`
|
||||
|
||||

|
||||
|
||||
右上角`Add account` 增加`2FA`
|
||||
|
||||

|
||||
|
||||
```yaml
|
||||
Issuer: 备注 可选
|
||||
Account name : 用户名 必填项
|
||||
Secret Key : Hotp或Totp的key 必填项
|
||||
```
|
||||
|
||||
|
||||
# OpenPGP
|
||||
|
||||
## 安装GPG
|
||||
|
||||
Windows 用户可下载 [Gpg4Win](https://gpg4win.org/download.html),Linux/macOS 用户使用对应包管理软件安装即可.
|
||||
|
||||
## 生成主密钥
|
||||
|
||||
```shell
|
||||
gpg --expert --full-gen-key #生成GPG KEY
|
||||
```
|
||||
|
||||
推荐使用`ECC`算法
|
||||
|
||||

|
||||
|
||||
```shell
|
||||
选择(11) ECC (set your own capabilities) # 设置自己的功能 主密钥只保留 Certify 功能,其他功能(Encr,Sign,Auth)使用子密钥
|
||||
# 子密钥分成三份,分别获得三个不同的功能
|
||||
# encr 解密功能
|
||||
# sign 签名功能
|
||||
# auth 登录验证功能
|
||||
```
|
||||
|
||||
```shell
|
||||
先选择 (S) Toggle the sign capability
|
||||
```
|
||||
|
||||

|
||||
|
||||
```
|
||||
之后输入q 退出
|
||||
```
|
||||
|
||||
键入1,选择默认算法
|
||||
|
||||

|
||||
|
||||
设置主密钥永不过期
|
||||
|
||||

|
||||
|
||||
填写信息,按照实际情况填写即可
|
||||
|
||||

|
||||
|
||||
```
|
||||
Windnows 下会弹出窗口输入密码,注意一定要保管好!!!
|
||||
```
|
||||
|
||||
```shell
|
||||
|
||||
```
|
||||
|
||||
```shell
|
||||
# 会自动生成吊销证书,注意保存到安全的地方
|
||||
gpg: AllowSetForegroundWindow(22428) failed: <20>ܾ<EFBFBD><DCBE><EFBFBD><EFBFBD>ʡ<EFBFBD>
|
||||
gpg: revocation certificate stored as 'C:\\Users\\Andorid\\AppData\\Roaming\\gnupg\\openpgp-revocs.d\\<此处为私钥>.rev'
|
||||
# 以上的REV文件即为吊销证书
|
||||
public and secret key created and signed.
|
||||
```
|
||||
|
||||
```shell
|
||||
pub ed25519 2022-01-02 [SC]
|
||||
<此处为Pub>
|
||||
uid <此处为Name> <此处为email>
|
||||
```
|
||||
|
||||
生成子密钥
|
||||
|
||||
```shell
|
||||
gpg --fingerprint --keyid-format long -K
|
||||
```
|
||||
|
||||
下面生成不同功能的子密钥,其中 `<fingerprint>` 为上面输出的密钥指纹,本示例中即为 `私钥`。最后的 `2y` 为密钥过期时间,可自行设置,如不填写默认永不过期。
|
||||
|
||||
```shell
|
||||
gpg --quick-add-key <fingerprint> cv25519 encr 2y
|
||||
gpg --quick-add-key <fingerprint> ed25519 auth 2y
|
||||
gpg --quick-add-key <fingerprint> ed25519 sign 2y
|
||||
```
|
||||
|
||||
再次查看目前的私钥,可以看到已经包含了这三个子密钥。
|
||||
|
||||
```shell
|
||||
gpg --fingerprint --keyid-format long -K
|
||||
```
|
||||
|
||||
上面生成了三种功能的子密钥(ssb),分别为加密(E)、认证(A)、签名(S),对应 `OpenPGP Applet` 中的三个插槽。由于 `ECC` 实现的原因,加密密钥的算法区别于其他密钥的算法。
|
||||
|
||||
加密密钥用于加密文件和信息。签名密钥主要用于给自己的信息签名,保证这真的是来自**我**的信息。认证密钥主要用于 SSH 登录。
|
||||
|
||||
## 备份GPG
|
||||
|
||||
```shell
|
||||
# 公钥
|
||||
gpg -ao public-key.pub --export <ed25519/16位>
|
||||
# 主密钥,请务必保存好!!!
|
||||
# 注意 key id 后面的 !,表示只导出这一个私钥,若没有的话默认导出全部私钥。
|
||||
gpg -ao sec-key.asc --export-secret-key <ed25519/16位>!
|
||||
# sign子密钥
|
||||
gpg -ao sign-key.asc --export-secret-key <ed25519/16位>!
|
||||
gpg -ao auth-key.asc --export-secret-key <ed25519/16位>!
|
||||
gpg -ao encr-key.asc --export-secret-key <ed25519/16位>!
|
||||
```
|
||||
|
||||
## 导入Canokey
|
||||
|
||||
```shell
|
||||
# 查看智能卡设备状态
|
||||
gpg --card-status
|
||||
# 写入GPG
|
||||
gpg --edit-key <ed25519/16位> # 为上方的sec-key
|
||||
# 选中第一个子密钥
|
||||
key 1
|
||||
# 写入到智能卡
|
||||
keytocard
|
||||
# 再次输入,取消选择
|
||||
key 1
|
||||
# 选择第二个子密钥
|
||||
key 2
|
||||
keytocard
|
||||
key 2
|
||||
key 3
|
||||
keytocard
|
||||
# 保存修改并退出
|
||||
save
|
||||
|
||||
#再次查看设备状态,可以看到此时子密钥标识符为 ssb>,表示本地只有一个指向 card-no: F1D0 xxxxxxxx 智能卡的指针,已不存在私钥。现在可以删除掉主密钥了,请再次确认你已安全备份好主密钥。
|
||||
gpg --card-status
|
||||
```
|
||||
## 删除本地密钥
|
||||
|
||||
```shell
|
||||
gpg --delete-secret-keys <ed25519/16位> # 为上方的sec-key
|
||||
```
|
||||
|
||||
为确保安全,也可直接删除 gpg 的工作目录:`%APPDATA%\gnupg`,Linux/macOS: `~/.gunpg`。
|
||||
|
||||
## 使用 Canokey
|
||||
|
||||
此时切换回日常使用的环境,首先导入公钥
|
||||
|
||||
```shell
|
||||
gpg --import public-key.pub
|
||||
```
|
||||
|
||||
然后设置子密钥指向 Canokey
|
||||
|
||||
```shell
|
||||
gpg --edit-card
|
||||
gpg/card> fetch
|
||||
```
|
||||
|
||||
此时查看本地的私钥,可以看到已经指向了 Canokey
|
||||
|
||||
```
|
||||
gpg --fingerprint --keyid-format long -K
|
||||
```
|
||||
|
||||
配置gpg路径
|
||||
|
||||
```bash
|
||||
git config --global gpg.program "C:\Program Files (x86)\GnuPG\bin\gpg.exe" --replace-all
|
||||
```
|
||||
|
||||
## Git Commit 签名
|
||||
|
||||
首先确保 Git 本地配置以及 GitHub 中的邮箱信息包含在 `UID` 中,然后设置 Git 来指定使用子密钥中的签名(S)密钥。
|
||||
|
||||
```shell
|
||||
git config --global user.signingkey <ed25519/16位> # 为上方的Sign密钥
|
||||
```
|
||||
|
||||
之后在 `git commit` 时增加 `-S` 参数即可使用 gpg 进行签名。也可在配置中设置自动 gpg 签名,此处不建议全局开启该选项,因为有的脚本可能会使用 `git am` 之类的涉及到 `commit` 的命令,如果全局开启的话会导致问题。
|
||||
|
||||
```shell
|
||||
git config commit.gpgsign true
|
||||
```
|
||||
|
||||
如果提交到 GitHub,前往 [GitHub SSH and GPG keys](https://github.com/settings/keys) 添加公钥。此处添加后,可以直接通过对应 GitHub ID 来获取公钥:`https://github.com/<yourid>.gpg`
|
||||
|
||||
## PIV
|
||||
|
||||
首先在Web端添加自己的私钥到智能卡,之后前往 [WinCrypt SSH Agent](https://github.com/buptczq/WinCryptSSHAgent) 下载并运行,此时查看 `ssh-agent` 读取到的公钥信息,把输出的公钥信息添加到服务器的 `~/.ssh/authorized_keys`
|
||||
|
||||
```shell
|
||||
# 设置环境池
|
||||
$Env:SSH_AUTH_SOCK="\\.\pipe\openssh-ssh-agent"
|
||||
# 查看ssh列表
|
||||
ssh-add -L
|
||||
```
|
||||
|
||||
此时连接 `ssh user@host`,会弹出提示输入 `PIN` 的页面,注意此时输入的是 `PIV Applet PIN`,输入后即可成功连接服务器。
|
||||
|
||||
```yaml
|
||||
tips: 可能会出现权限不够的情况,需要禁用Windows服务OpenSSH Authentication Agent
|
||||
```
|
||||
|
||||
最后可以把该程序快捷方式添加到启动目录 `%AppData%\Microsoft\Windows\Start Menu\Programs\Startup`,方便直接使用。
|
||||
@@ -1,67 +0,0 @@
|
||||
---
|
||||
title: "如何使用FFmpeg处理音视频文件"
|
||||
description: 本文提供了FFmpeg处理音视频文件的完整指南,包括将单张图片转换为视频、拼接多个视频、设置转场特效等多种操作。
|
||||
date: 2022-07-25T14:05:04+08:00
|
||||
draft: true
|
||||
slug: ffmpeg
|
||||
image:
|
||||
categories: ffmpeg
|
||||
tags: ffmpeg
|
||||
---
|
||||
|
||||
# `ffmpeg`图片转视频
|
||||
|
||||
使用单张图片生成5秒视频
|
||||
|
||||
```bash
|
||||
# -loop 1 指定开启单帧图片loop
|
||||
# -t 5 指定loop时长为5秒
|
||||
# -i input 指定输入图片文件路径 示例:pic.jpg
|
||||
# -pix_fmt 指定编码格式为yuv420p
|
||||
# -y 若输出文件已存在,则强制进行覆盖。
|
||||
# ffmpeg会根据输出文件后缀,自动选择编码格式。
|
||||
# 也可以使用 -f 指定输出格式
|
||||
ffmpeg -loop 1 -t 5 -i <filename>.jpg -pix_fmt yuv420p -y output.ts
|
||||
```
|
||||
|
||||
# `ffmpeg`拼接视频
|
||||
|
||||
```bash
|
||||
# windows
|
||||
# -i input 指定需要合并的文件,使用concat进行合并.示例:"concat:0.ts|1.ts|2.ts"
|
||||
# -vcodec 指定视频编码器的参数为copy
|
||||
# -acodec 指定音频编码器的参数为copy
|
||||
# -y 若输出文件已存在,则强制进行覆盖。
|
||||
ffmpeg -i "concat:0.ts|1.ts" -vcodec copy -acodec copy -y output.ts
|
||||
```
|
||||
|
||||
# `ffmpeg`设置转场特效
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
ffmpeg -i v0.mp4 -i v1.mp4 -i v2.mp4 -i v3.mp4 -i v4.mp4 -filter_complex \
|
||||
"[0][1:v]xfade=transition=fade:duration=1:offset=3[vfade1]; \
|
||||
[vfade1][2:v]xfade=transition=fade:duration=1:offset=10[vfade2]; \
|
||||
[vfade2][3:v]xfade=transition=fade:duration=1:offset=21[vfade3]; \
|
||||
[vfade3][4:v]xfade=transition=fade:duration=1:offset=25,format=yuv420p; \
|
||||
[0:a][1:a]acrossfade=d=1[afade1]; \
|
||||
[afade1][2:a]acrossfade=d=1[afade2]; \
|
||||
[afade2][3:a]acrossfade=d=1[afade3]; \
|
||||
[afade3][4:a]acrossfade=d=1" \
|
||||
-movflags +faststart out.mp4
|
||||
```
|
||||
|
||||
| 输入文件 | 输入文件的视频总长 | + | previous xfade `offset` | - | xfade `duration` | `offset` = |
|
||||
| :------- | :----------------- | :--: | :---------------------- | :--: | :--------------- | :--------- |
|
||||
| `v0.mp4` | 4 | + | 0 | - | 1 | 3 |
|
||||
| `v1.mp4` | 8 | + | 3 | - | 1 | 10 |
|
||||
| `v2.mp4` | 12 | + | 10 | - | 1 | 21 |
|
||||
| `v3.mp4` | 5 | + | 21 | - | 1 | 25 |
|
||||
|
||||
// 将音频转为单声道
|
||||
|
||||
```
|
||||
ffmpeg -i .\1.mp3 -ac 1 -ar 44100 -ab 16k -vol 50 -f 1s.mp3
|
||||
ffmpeg -i one.ts -i 1s.mp3 -map 0:v -map 1:a -c:v copy -shortest -af apad -y one1.ts
|
||||
```
|
||||
|
||||
@@ -1,121 +0,0 @@
|
||||
---
|
||||
title: "使用arm交叉编译工具并解决GLIBC版本不匹配的问题"
|
||||
description: 介绍如何使用arm交叉编译工具来编译Go程序,并解决在arm平台上运行时出现GLIBC版本不匹配的问题。
|
||||
date: 2022-06-10T15:00:26+08:00
|
||||
draft: false
|
||||
slug: go-arm
|
||||
image:
|
||||
categories:
|
||||
- Go
|
||||
tags:
|
||||
- Arm
|
||||
- Go
|
||||
- GLIBC
|
||||
---
|
||||
|
||||
1. 下载 ARM 交叉编译工具,可以从官方网站下载。比如,可以从如下链接下载 GNU 工具链:[https://developer.arm.com/downloads/-/gnu-a](https://developer.arm.com/downloads/-/gnu-a)
|
||||
|
||||
示例:https://developer.arm.com/-/media/Files/downloads/gnu-a/10.3-2021.07/binrel/gcc-arm-10.3-2021.07-mingw-w64-i686-aarch64-none-elf.tar.xz
|
||||
|
||||
2. 设置 Go ARM 交叉编译环境变量。具体来说,需要设置以下变量:
|
||||
|
||||
```ruby
|
||||
$env:GOOS="linux"
|
||||
$env:GOARCH="arm64"
|
||||
$env:CGO_ENABLED=1
|
||||
$env:CC="D:\arm\gcc-arm-10.3-2021.07-mingw-w64-i686-aarch64-none-linux-gnu\bin\aarch64-none-linux-gnu-gcc.exe"
|
||||
$env:CXX="D:\arm\gcc-arm-10.3-2021.07-mingw-w64-i686-aarch64-none-linux-gnu\bin\aarch64-none-linux-gnu-g++.exe"
|
||||
```
|
||||
|
||||
3. 在 ARM 上运行程序时可能会出现如下错误:
|
||||
|
||||
```bash
|
||||
./bupload: /lib/aarch64-linux-gnu/libc.so.6: version `GLIBC_2.28' not found (required by ./bupload)
|
||||
./bupload: /lib/aarch64-linux-gnu/libc.so.6: version `GLIBC_2.32' not found (required by ./bupload)
|
||||
./bupload: /lib/aarch64-linux-gnu/libc.so.6: version `GLIBC_2.33' not found (required by ./bupload)
|
||||
```
|
||||
|
||||
这是因为程序需要使用较新版本的 GLIBC 库,而 ARM 上安装的库版本较旧。可以通过以下步骤来解决这个问题:
|
||||
|
||||
4. 查看当前系统中 libc 库所支持的版本:
|
||||
|
||||
```bash
|
||||
strings /lib/aarch64-linux-gnu/libc.so.6 | grep GLIBC_
|
||||
```
|
||||
|
||||
5. 备份整个 `/lib` 目录和 `/usr/include` 目录,以便稍后还原。
|
||||
6. 从 GNU libc 官方网站下载对应版本的 libc 库。例如,可以从如下链接下载 2.35 版本的 libc 库:[http://ftp.gnu.org/gnu/glibc/glibc-2.35.tar.xz](http://ftp.gnu.org/gnu/glibc/glibc-2.35.tar.xz)
|
||||
7. 解压 libc 库:
|
||||
|
||||
```
|
||||
xz -d glibc-2.35.tar.xz
|
||||
tar xvf glibc-2.35.tar glibc-2.35
|
||||
```
|
||||
|
||||
8. 创建并进入 build 目录:
|
||||
|
||||
```bash
|
||||
mkdir build
|
||||
cd build
|
||||
```
|
||||
|
||||
9. 配置 libc 库的安装选项:
|
||||
|
||||
```javascript
|
||||
../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin
|
||||
```
|
||||
|
||||
10. 编译并安装 libc 库:
|
||||
|
||||
```go
|
||||
make -j4
|
||||
make install
|
||||
```
|
||||
|
||||
接下来是关于 `make` 报错的部分:
|
||||
|
||||
```yaml
|
||||
asm/errno.h: No such file or directory
|
||||
```
|
||||
|
||||
这个报错是因为 `errno.h` 文件中包含了 `asm/errno.h` 文件,但是找不到这个文件。为了解决这个问题,我们需要创建一个软链接:
|
||||
|
||||
```bash
|
||||
ln -s /usr/include/asm-generic /usr/include/asm
|
||||
```
|
||||
|
||||
然后又出现了另一个报错:
|
||||
|
||||
```bash
|
||||
/usr/include/aarch64-linux-gnu/asm/sigcontext.h: No such file or directory
|
||||
```
|
||||
|
||||
这个问题也可以通过重新安装`linux-libc-dev`后创建软链接来解决:
|
||||
|
||||
```bash
|
||||
# find / -name sigcontext.h
|
||||
sudo apt-get install --reinstall linux-libc-dev
|
||||
ln -s /usr/include/aarch64-linux-gnu/asm/sigcontext.h /usr/include/asm/sigcontext.h
|
||||
```
|
||||
|
||||
接下来,还有一个报错:
|
||||
|
||||
```yaml
|
||||
asm/sve_context.h: No such file or directory
|
||||
```
|
||||
|
||||
这个报错是因为最新的 Linux 内核在启用 ARM Scalable Vector Extension (SVE) 后,需要包含 `asm/sve_context.h` 文件。我们需要创建一个软链接来解决这个问题:
|
||||
|
||||
```bash
|
||||
# find / -name sve_context.h
|
||||
ln -s /usr/include/aarch64-linux-gnu/asm/sve_context.h /usr/include/asm/sve_context.h
|
||||
```
|
||||
|
||||
最后,还需要创建一个软链接:
|
||||
|
||||
```bash
|
||||
# find / -name byteorder.h
|
||||
ln -s /usr/include/aarch64-linux-gnu/asm/byteorder.h /usr/include/asm/byteorder.h
|
||||
```
|
||||
|
||||
完成以上步骤后,我们再次执行 `make` 命令,就应该可以顺利地编译和安装 glibc 了。
|
||||
@@ -1,173 +0,0 @@
|
||||
---
|
||||
title: "Go使用gRPC进行通信"
|
||||
description: RPC是远程过程调用的简称,是分布式系统中不同节点间流行的通信方式。
|
||||
date: 2022-05-26T14:17:33+08:00
|
||||
draft: false
|
||||
slug: go-grpc
|
||||
image:
|
||||
categories:
|
||||
- Go
|
||||
tags:
|
||||
- Go
|
||||
- gRPC
|
||||
---
|
||||
|
||||
# 安装`gRPC`和`Protoc`
|
||||
|
||||
## 安装`protobuf`
|
||||
|
||||
```bash
|
||||
go get -u google.golang.org/protobuf
|
||||
go get -u google.golang.org/protobuf/proto
|
||||
go get -u google.golang.org/protobuf/protoc-gen-go
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 安装`Protoc`
|
||||
|
||||
```shell
|
||||
# 下载二进制文件并添加至环境变量
|
||||
https://github.com/protocolbuffers/protobuf/releases
|
||||
```
|
||||
|
||||
安装`Protoc`插件`protoc-gen-go`
|
||||
|
||||
```shell
|
||||
# go install 会自动编译项目并添加至环境变量中
|
||||
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest
|
||||
```
|
||||
|
||||
```shell
|
||||
#protoc-gen-go 文档地址
|
||||
https://developers.google.com/protocol-buffers/docs/reference/go-generated
|
||||
```
|
||||
|
||||
# 创建`proto`文件并定义服务
|
||||
|
||||
## 新建 `task.proto`文件
|
||||
|
||||
```shell
|
||||
touch task.proto
|
||||
```
|
||||
|
||||
## 编写`task.proto`
|
||||
|
||||
```protobuf
|
||||
// 指定proto版本
|
||||
syntax = "proto3";
|
||||
// 指定包名
|
||||
package task;
|
||||
// 指定输出 go 语言的源码到哪个目录和 包名
|
||||
// 主要 目录和包名用 ; 隔开
|
||||
// 将在当前目录生成 task.pb.go
|
||||
// 也可以只填写 "./",会生成的包名会变成 "----"
|
||||
option go_package = "./;task";
|
||||
|
||||
// 指定RPC的服务名
|
||||
service TaskService {
|
||||
// 调用 AddTaskCompletion 方法
|
||||
rpc AddTaskCompletion(request) returns (response);
|
||||
}
|
||||
|
||||
// RPC TaskService服务,AddTaskCompletion函数的请求参数,即消息
|
||||
message request {
|
||||
uint32 id = 1;//任务id
|
||||
string module = 2;//所属模块
|
||||
int32 value = 3;//此次完成值
|
||||
string guid = 4;//用户id
|
||||
}
|
||||
// RPC TaskService服务,TaskService函数的返回值,即消息
|
||||
message response{
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## 使用`Protoc`来生成Go代码
|
||||
|
||||
```bash
|
||||
protoc --go_out=. --go-grpc_out=. <要进行生成代码的文件>.proto
|
||||
# example
|
||||
protoc --go_out=. --go-grpc_out=. .\task.proto
|
||||
```
|
||||
|
||||
这样生成会生成两个`.go`文件,一个是对应消息`task.pb.go`,一个对应服务接口`task_grpc.pb.go`。
|
||||
|
||||
在`task_grpc.pb.go`中,在我们定义的服务接口中,多增加了一个私有的接口方法:
|
||||
`mustEmbedUnimplementedTaskServiceServer()`
|
||||
|
||||
# 使用`Go`监听`gRPC`服务端及客户端
|
||||
|
||||
## 监听服务端
|
||||
|
||||
并有生成的一个`UnimplementedTaskServiceServer`结构体来实现了所有的服务接口。因此,在我们自己实现的服务类中,需要继承这个结构体,如:
|
||||
|
||||
```go
|
||||
// 用于实现grpc服务 TaskServiceServer 接口
|
||||
type TaskServiceImpl struct {
|
||||
// 需要继承结构体 UnimplementedServiceServer 或mustEmbedUnimplementedTaskServiceServer
|
||||
task.mustEmbedUnimplementedTaskServiceServer()
|
||||
}
|
||||
|
||||
func main() {
|
||||
// 创建Grpc服务
|
||||
// 创建tcp连接
|
||||
listener, err := net.Listen("tcp", ":8082")
|
||||
if err != nil {
|
||||
fmt.Println(err)
|
||||
return
|
||||
}
|
||||
// 创建grpc服务
|
||||
grpcServer := grpc.NewServer()
|
||||
// 此函数在task.pb.go中,自动生成
|
||||
task.RegisterTaskServiceServer(grpcServer, &TaskServiceImpl{})
|
||||
// 在grpc服务上注册反射服务
|
||||
reflection.Register(grpcServer)
|
||||
// 启动grpc服务
|
||||
err = grpcServer.Serve(listener)
|
||||
if err != nil {
|
||||
fmt.Println(err)
|
||||
return
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func (s *TaskServiceImpl) AddTaskCompletion(ctx context.Context, in *task.Request) (*task.Response, error) {
|
||||
fmt.Println("收到一个Grpc 请求, 请求参数为", in.Guid)
|
||||
r := &task.Response{
|
||||
}
|
||||
return r, nil
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
然后在`TaskService`上实现我们的服务接口。
|
||||
|
||||
|
||||
## 客户端
|
||||
|
||||
```go
|
||||
conn, err := grpc.Dial("127.0.0.1:8082", grpc.WithInsecure())
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
defer conn.Close()
|
||||
// 创建grpc客户端
|
||||
client := task.NewTaskServiceClient(conn)
|
||||
// 创建请求
|
||||
req := &task.Request{
|
||||
Id: 1,
|
||||
Module: "test",
|
||||
Value: 3,
|
||||
Guid: "test",
|
||||
}
|
||||
// 调用rpc TaskService AddTaskCompletion函数
|
||||
response, err := client.AddTaskCompletion(context.Background(), req)
|
||||
if err != nil {
|
||||
log.Println(err)
|
||||
return
|
||||
}
|
||||
log.Println(response)
|
||||
```
|
||||
|
||||
[本文参考](https://www.cnblogs.com/whuanle/p/14588031.html)
|
||||
@@ -1,98 +0,0 @@
|
||||
---
|
||||
title: "Go语言解析Xml"
|
||||
slug: "go-xml"
|
||||
date: 2022-05-20T14:38:05+08:00
|
||||
draft: false
|
||||
description: "使用Go简简单单的解析Xml!"
|
||||
tags:
|
||||
- Go
|
||||
- Xml
|
||||
categories:
|
||||
- Go
|
||||
---
|
||||
|
||||
# 开始之前
|
||||
|
||||
```go
|
||||
import "encoding/xml"
|
||||
```
|
||||
|
||||
## 简单的`Xml`解析
|
||||
|
||||
### 1.假设我们解析的`Xml`内容如下:
|
||||
|
||||
```xml
|
||||
<feed>
|
||||
<person name="initcool" id="1" age=18 />
|
||||
</feed>
|
||||
```
|
||||
|
||||
<!--more-->
|
||||
|
||||
### 2.接着我们构造对应的结构体
|
||||
|
||||
```go
|
||||
type Feed struct {
|
||||
XMLName xml.Name `xml:"feed"`
|
||||
Person struct{
|
||||
Name string `xml:"name"`
|
||||
Id string `xml:"id"`
|
||||
Age int `xml:"age"`
|
||||
} `xml:"person"`
|
||||
}
|
||||
```
|
||||
|
||||
### 3.对`Xml`数据进行反序列化
|
||||
|
||||
```go
|
||||
var feed Feed
|
||||
|
||||
// 读取Xml文件,并返回字节流
|
||||
content,err := ioutil.ReadFile(XmlFilename)
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
|
||||
// 将读取到的内容反序列化到feed
|
||||
xml.Unmarshal(content,&feed)
|
||||
```
|
||||
|
||||
## 带有命名空间的`Xml`解析
|
||||
|
||||
部分`xml`文件会带有`命名空间`(`Namespace`),也就是冒号左侧的内容,此时我们需要在`go`结构体的`tag` 中加入`命名空间`。
|
||||
|
||||
### 1.带有命名空间(Namespace)的`Xml`文件
|
||||
|
||||
```xml
|
||||
<feed xmlns:yt="http://www.youtube.com/xml/schemas/2015" xmlns:media="http://search.yahoo.com/mrss/" xmlns="http://www.w3.org/2005/Atom">
|
||||
<!-- yt即是命名空间 -->
|
||||
<yt:videoId>XXXXXXX</yt:videoId>
|
||||
<!-- media是另一个命名空间 -->
|
||||
<media:community></media:community>
|
||||
</feed>
|
||||
```
|
||||
|
||||
### 2.针对命名空间构造结构体
|
||||
|
||||
```go
|
||||
type Feed struct {
|
||||
XMLName xml.Name `xml:"feed"` // 指定最外层的标签为feed
|
||||
VideoId string `xml:"http://www.youtube.com/xml/schemas/2015 videoId"`
|
||||
Community string `xml:"http://search.yahoo.com/mrss/ community"`
|
||||
}
|
||||
```
|
||||
|
||||
### 3.对`Xml`数据进行反序列化
|
||||
|
||||
```go
|
||||
var feed Feed
|
||||
|
||||
// 读取Xml文件,并返回字节流
|
||||
content,err := ioutil.ReadFile(XmlFilename)
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
|
||||
// 将读取到的内容反序列化到feed
|
||||
xml.Unmarshal(content,&feed)
|
||||
```
|
||||
@@ -1,36 +0,0 @@
|
||||
---
|
||||
title: "Hugo使用指南!"
|
||||
slug: "hugo"
|
||||
draft: false
|
||||
date: 2022-05-20T10:23:53+08:00
|
||||
description: "快速上手hugo!"
|
||||
tags:
|
||||
- Go
|
||||
- Hugo
|
||||
categories:
|
||||
- Go
|
||||
---
|
||||
查看Hugo版本号
|
||||
|
||||
```bash
|
||||
hugo version
|
||||
```
|
||||
|
||||
新建一个Hugo页面
|
||||
|
||||
```
|
||||
hugo new site <siteName>
|
||||
```
|
||||
|
||||
设置主题
|
||||
|
||||
```bash
|
||||
cd <siteName>
|
||||
git init
|
||||
|
||||
# 设置为 Stack主题
|
||||
git clone https://github.com/CaiJimmy/hugo-theme-stack/ themes/hugo-theme-stack
|
||||
git submodule add https://github.com/CaiJimmy/hugo-theme-stack/ themes/hugo-theme-stack
|
||||
```
|
||||
|
||||
部署Hugo到github
|
||||
@@ -1,67 +0,0 @@
|
||||
---
|
||||
title: "Linux部署DHCP服务"
|
||||
description: Debian下使用docker镜像部署DHCP服务
|
||||
date: 2022-05-23T11:11:40+08:00
|
||||
draft: false
|
||||
slug: linux-dhcp
|
||||
image:
|
||||
categories: Linux
|
||||
tags:
|
||||
- Linux
|
||||
- DHCP
|
||||
---
|
||||
|
||||
拉取`networkboot/dhcpd`镜像
|
||||
|
||||
```shell
|
||||
docker pull networkboot/dhcpd
|
||||
```
|
||||
|
||||
新建`data/dhcpd.conf`文件
|
||||
|
||||
```shell
|
||||
touch /data/dhcpd.conf
|
||||
```
|
||||
|
||||
修改`data/dhcpd.conf`文件
|
||||
|
||||
```
|
||||
subnet 204.254.239.0 netmask 255.255.255.224 {
|
||||
option subnet-mask 255.255.0.0;
|
||||
option domain-name "cname.nmslwsnd.com";
|
||||
option domain-name-servers 8.8.8.8;
|
||||
range 204.254.239.10 204.254.239.30;
|
||||
}
|
||||
```
|
||||
|
||||
修改`/etc/network/interfaces`
|
||||
|
||||
```
|
||||
# The loopback network interface (always required)
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
|
||||
# Get our IP address from any DHCP server
|
||||
auto dhcp
|
||||
iface dhcp inet static
|
||||
address 204.254.239.0
|
||||
netmask 255.255.255.224
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
获取帮助命令
|
||||
|
||||
```shell
|
||||
docker run -it --rm networkboot/dhcpd man dhcpd.conf
|
||||
```
|
||||
|
||||
运行`DHCP`服务
|
||||
|
||||
```shell
|
||||
docker run -it --rm --init --net host -v "/data":/data networkboot/dhcpd <网卡名称>
|
||||
# 示例
|
||||
docker run -it --rm --init --net host -v "/data":/data networkboot/dhcpd dhcp
|
||||
```
|
||||
|
||||
@@ -1,36 +0,0 @@
|
||||
---
|
||||
title: "Linux Shell"
|
||||
description:
|
||||
date: 2022-05-21T10:02:09+08:00
|
||||
draft: false
|
||||
Hidden: true
|
||||
slug: linux-shell
|
||||
image:
|
||||
categories:
|
||||
Linux
|
||||
tag:
|
||||
Linux
|
||||
Shell
|
||||
---
|
||||
|
||||
Linux守护进程:no_good:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
# nohup.sh
|
||||
while true
|
||||
do
|
||||
# -f 后跟进程名,判断进程是否正在运行
|
||||
if [ `pgrep -f <ProcessName> | wc -l` -eq 0 ];then
|
||||
echo "进程已终止"
|
||||
push
|
||||
# /dev/null 无输出日志
|
||||
nohup ./<ProcessName> > /dev/null 2>&1 &
|
||||
else
|
||||
echo "进程正在运行"
|
||||
fi
|
||||
# 每隔1分钟检查一次
|
||||
sleep 1m
|
||||
done
|
||||
```
|
||||
|
||||
@@ -1,65 +0,0 @@
|
||||
---
|
||||
title: "Linux"
|
||||
description:
|
||||
date: 2022-09-08T15:19:00+08:00
|
||||
draft: true
|
||||
slug: linux
|
||||
image:
|
||||
categories:
|
||||
- Linux
|
||||
tags:
|
||||
- Linux
|
||||
---
|
||||
|
||||
```bash
|
||||
# 使用cd 进入到上一个目录
|
||||
cd -
|
||||
```
|
||||
|
||||
复制和粘贴
|
||||
|
||||
```bash
|
||||
ctrl + shift + c
|
||||
ctrl + shift + v
|
||||
```
|
||||
|
||||
|
||||
|
||||
快速移动
|
||||
|
||||
```bash
|
||||
# 移动到行首
|
||||
ctrl + a
|
||||
# 移动到行尾
|
||||
ctrl + e
|
||||
```
|
||||
|
||||
快速删除
|
||||
|
||||
```bash
|
||||
# 删除光标之前的内容
|
||||
ctrl + u
|
||||
# 删除光标之后的内容
|
||||
ctrl + k
|
||||
# 恢复之前删除的内容
|
||||
ctrl + y
|
||||
```
|
||||
|
||||
不适用cat
|
||||
|
||||
```
|
||||
使用less 查看 顶部的文件
|
||||
less filename
|
||||
```
|
||||
|
||||
使用alt+backspace删除,以单词为单位
|
||||
|
||||
```
|
||||
tcpdump host 1.1.1.1
|
||||
```
|
||||
|
||||
```
|
||||
# 并行执行命令 Parallel
|
||||
find . -type f -name '*.html' -print | parallel gzip
|
||||
```
|
||||
|
||||
24
backend/content/posts/loco-rs-framework.md
Normal file
24
backend/content/posts/loco-rs-framework.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 游黄山记(中)
|
||||
slug: loco-rs-framework
|
||||
description: 钱谦益《游黄山记》中篇,适合测试中文长文、检索与段落锚点。
|
||||
category: 古籍游记
|
||||
post_type: article
|
||||
pinned: false
|
||||
status: published
|
||||
visibility: public
|
||||
noindex: false
|
||||
tags:
|
||||
- 钱谦益
|
||||
- 黄山
|
||||
- 游记
|
||||
- 长文测试
|
||||
---
|
||||
|
||||
# 游黄山记(中)
|
||||
|
||||
由祥符寺度石桥而北,逾慈光寺,行数里,径朱砂庵而上。过此取道钵盂、老人两峰之间,峰趾相并,两崖合遝,弥望削成。
|
||||
|
||||
憩桃源庵,指天都为诸峰之中峰,山形络绎,未有以殊异也。云生峰腰,层叠如裼衣焉。
|
||||
|
||||
清晓,出文殊院,神鸦背行而先。避莲华沟险,从支径右折,险益甚。上平天矼,转始信峰,经散花坞,看扰龙松。
|
||||
@@ -1,569 +0,0 @@
|
||||
---
|
||||
title: "mysql个人常用命令及操作"
|
||||
description:
|
||||
date: 2021-09-21T16:13:24+08:00
|
||||
draft: true
|
||||
slug: mysql
|
||||
image:
|
||||
categories:
|
||||
- Database
|
||||
tags:
|
||||
- Linux
|
||||
- Mysql
|
||||
- Sql
|
||||
---
|
||||
|
||||
启动`mysql`
|
||||
|
||||
```bash
|
||||
sudo service mysql start
|
||||
```
|
||||
|
||||
使用`root`账户登录`mysql`
|
||||
|
||||
```bash
|
||||
sudo mysql -u root
|
||||
```
|
||||
|
||||
查看数据库信息
|
||||
|
||||
```mysql
|
||||
show databases;
|
||||
```
|
||||
|
||||
新增数据库
|
||||
|
||||
```mysql
|
||||
create database <新增的数据库名>;
|
||||
# 示例,新增一个名为gradesystem的数据库
|
||||
create database gradesystem;
|
||||
|
||||
```
|
||||
|
||||
切换数据库
|
||||
|
||||
```mysql
|
||||
use <切换的数据库名>;
|
||||
# 示例,切换至gradesystem数据库
|
||||
use gradesystem;
|
||||
```
|
||||
|
||||
查看数据库中的表
|
||||
|
||||
```mysql
|
||||
# 查看数据库中所有的表
|
||||
show tables;
|
||||
```
|
||||
|
||||
新增表
|
||||
|
||||
```mysql
|
||||
# MySQL不区分大小写
|
||||
CREATE TABLE student(
|
||||
sid int NOT NULL AUTO_INCREMENT,
|
||||
sname varchar(20) NOT NULL,
|
||||
gender varchar(10) NOT NULL,
|
||||
PRIMARY KEY(sid)
|
||||
);
|
||||
# 新增一个表名为学生的表。
|
||||
# AUTO_INCREMENT, 自动地创建主键字段的值。
|
||||
# PRIMARY KEY(sid) 设置主键为sid
|
||||
CREATE TABLE course(
|
||||
cid int not null auto_increment,
|
||||
cname varchar(20) not null,
|
||||
primary key(cid)
|
||||
);
|
||||
# 新增一个表名为课程的表。
|
||||
# primary key(cid) 设置主键为cid
|
||||
|
||||
CREATE TABLE mark(
|
||||
mid int not null auto_increment,
|
||||
sid int not null,
|
||||
cid int not null,
|
||||
score int not null,
|
||||
primary key(mid),
|
||||
foreign key(sid) references student(sid),
|
||||
foreign key(cid) references course(cid)
|
||||
);
|
||||
# 新增一个表明为mark的表
|
||||
# primary key(cid) 设置主键为cid
|
||||
# foreign 设置外键为sid
|
||||
# foreign 设置外键为cid
|
||||
|
||||
insert into student values(1,'Tom','male'),(2,'Jack','male'),(3,'Rose','female');
|
||||
# 向student表插入数据,sid为1,sname为'Tom',gender为'male'
|
||||
|
||||
insert into course values(1,'math'),(2,'physics'),(3,'chemistry');
|
||||
# 向course表插入数据,sid为1,cname为'math'
|
||||
|
||||
insert into mark values(1,1,1,80);
|
||||
# 向mark表插入数据,mid为1,sid为1,cid为1,score为80
|
||||
```
|
||||
|
||||
### 向数据库插入数据
|
||||
|
||||
```mysql
|
||||
source <数据库文件所在目录>
|
||||
|
||||
|
||||
```
|
||||
|
||||
## SELECT语句查询
|
||||
|
||||
SELECT 语句的基本格式为:
|
||||
|
||||
```bash
|
||||
SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
|
||||
```
|
||||
|
||||
```mysql
|
||||
select name,age from employee;
|
||||
# 查看employee的name列和age列
|
||||
|
||||
select name,age from employee where age > 25;
|
||||
# 筛选出age 大于25的结果
|
||||
|
||||
select name,age,phone from employee where name = 'Mary';
|
||||
# 筛选出name为'Mary'的name,age,phone
|
||||
|
||||
select name,age,phone from employee where age < 25 or age >30;
|
||||
# 筛选出age小于30或大于25的name,age,phone
|
||||
|
||||
select name,age,phone from employee where age > 25 and age < 30;
|
||||
# 筛选出age大于25且小于30的name,age,phone
|
||||
|
||||
select name,age,phone from employee where age between 25 and 30;
|
||||
# 筛选出包含25和30的,name,age,phone
|
||||
|
||||
select name,age,phone,in_dpt from employee where in_dpt in('dpt3','dpt4');
|
||||
# 筛选出在dpt3或dpt4里面的name,age,phone,in_dpt
|
||||
|
||||
select name,age,phone,in_dpt from employee where in_dpt not in('dpt1','dpt3');
|
||||
# 筛选出不在dpt1和dpt3的name,age,phone,in_dpt
|
||||
|
||||
|
||||
```
|
||||
|
||||
## 通配符
|
||||
|
||||
关键字 **LIKE** 可用于实现模糊查询,常见于搜索功能中。
|
||||
|
||||
和 LIKE 联用的通常还有通配符,代表未知字符。SQL 中的通配符是 `_` 和 `%` 。其中 `_` 代表一个**未指定**字符,`%` 代表**不定个**未指定字符
|
||||
|
||||
```mysql
|
||||
select name,age,phone from employee where phone like '1101__';
|
||||
# 筛选出1101开头的六位数字的name,age,phone
|
||||
|
||||
select name,age,phone from employee where name like 'J%';
|
||||
# 筛选出name位J开头的人的name,age,phone
|
||||
```
|
||||
|
||||
## 排序
|
||||
|
||||
为了使查询结果看起来更顺眼,我们可能需要对结果按某一列来排序,这就要用到 **ORDER BY** 排序关键词。默认情况下,**ORDER BY** 的结果是**升序**排列,而使用关键词 **ASC** 和 **DESC** 可指定**升序**或**降序**排序。 比如,我们**按 salary 降序排列**,SQL 语句为
|
||||
|
||||
```mysql
|
||||
select name,age,salary,phone from employee order by salary desc;
|
||||
# salary列按降序排列
|
||||
select name,age,salary,phone from employee order by salary;
|
||||
# 不加 DESC 或 ASC 将默认按照升序排列。
|
||||
```
|
||||
|
||||
## SQL 内置函数和计算
|
||||
|
||||
置函数,这些函数都对 SELECT 的结果做操作:
|
||||
|
||||
| 函数名: | COUNT | SUM | AVG | MAX | MIN |
|
||||
| -------- | ----- | ---- | -------- | ------ | ------ |
|
||||
| 作用: | 计数 | 求和 | 求平均值 | 最大值 | 最小值 |
|
||||
|
||||
> 其中 COUNT 函数可用于任何数据类型(因为它只是计数),而 SUM 、AVG 函数都只能对数字类数据类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
|
||||
|
||||
|
||||
|
||||
```mysql
|
||||
select max(salary) as max_salary,min(salary) from employee;
|
||||
# 使用as关键字可以给值重命名,
|
||||
```
|
||||
|
||||
## 连接查询
|
||||
|
||||
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 **(join)** 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
|
||||
|
||||
```mysql
|
||||
select id,name,people_num from employee,department where employee.in_dpt = department.dpt_name order by id;
|
||||
# 这条语句查询出的是,各员工所在部门的人数,其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表:
|
||||
|
||||
select id,name,people_num from employee join department on employee.in_dpt = department.dpt_name order by id;
|
||||
# 另一个连接语句格式是使用 JOIN ON 语法,刚才的语句等同于以上语句
|
||||
```
|
||||
|
||||
## 删除数据库
|
||||
|
||||
```mysql
|
||||
drop database test_01;
|
||||
# 删除名为test_01的数据库;
|
||||
```
|
||||
|
||||
### 修改表
|
||||
|
||||
重命名一张表的语句有多种形式,以下 3 种格式效果是一样的:
|
||||
|
||||
```sql
|
||||
RENAME TABLE 原名 TO 新名字;
|
||||
|
||||
ALTER TABLE 原名 RENAME 新名;
|
||||
|
||||
ALTER TABLE 原名 RENAME TO 新名;
|
||||
```
|
||||
|
||||
进入数据库 mysql_shiyan :
|
||||
|
||||
```mysql
|
||||
use mysql_shiyan
|
||||
```
|
||||
|
||||
使用命令尝试修改 `table_1` 的名字为 `table_2` :
|
||||
|
||||
```mysql
|
||||
RENAME TABLE table_1 TO table_2;
|
||||
```
|
||||
|
||||
删除一张表的语句,类似于刚才用过的删除数据库的语句,格式是这样的:
|
||||
|
||||
```sql
|
||||
DROP TABLE 表名字;
|
||||
```
|
||||
|
||||
比如我们把 `table_2` 表删除:
|
||||
|
||||
```mysql
|
||||
DROP TABLE table_2;
|
||||
```
|
||||
|
||||
#### 增加一列
|
||||
|
||||
在表中增加一列的语句格式为:
|
||||
|
||||
```sql
|
||||
ALTER TABLE 表名字 ADD COLUMN 列名字 数据类型 约束;
|
||||
或:
|
||||
ALTER TABLE 表名字 ADD 列名字 数据类型 约束;
|
||||
```
|
||||
|
||||
现在 employee 表中有 `id、name、age、salary、phone、in_dpt` 这 6 个列,我们尝试加入 `height` (身高)一个列并指定 DEFAULT 约束:
|
||||
|
||||
```mysql
|
||||
ALTER TABLE employee ADD height INT(4) DEFAULT 170;
|
||||
```
|
||||
|
||||
可以发现:新增加的列,被默认放置在这张表的最右边。如果要把增加的列插入在指定位置,则需要在语句的最后使用 AFTER 关键词(**“AFTER 列 1” 表示新增的列被放置在 “列 1” 的后面**)。
|
||||
|
||||
> 提醒:语句中的 INT(4) 不是表示整数的字节数,而是表示该值的显示宽度,如果设置填充字符为 0,则 170 显示为 0170
|
||||
|
||||
比如我们新增一列 `weight`(体重) 放置在 `age`(年龄) 的后面:
|
||||
|
||||
```mysql
|
||||
ALTER TABLE employee ADD weight INT(4) DEFAULT 120 AFTER age;
|
||||
```
|
||||
|
||||
|
||||
|
||||
上面的效果是把新增的列加在某位置的后面,如果想放在第一列的位置,则使用 `FIRST` 关键词,如语句:
|
||||
|
||||
```sql
|
||||
ALTER TABLE employee ADD test INT(10) DEFAULT 11 FIRST;
|
||||
```
|
||||
|
||||
#### 删除一列
|
||||
|
||||
删除表中的一列和刚才使用的新增一列的语句格式十分相似,只是把关键词 `ADD` 改为 `DROP` ,语句后面不需要有数据类型、约束或位置信息。具体语句格式:
|
||||
|
||||
```sql
|
||||
ALTER TABLE 表名字 DROP COLUMN 列名字;
|
||||
|
||||
或: ALTER TABLE 表名字 DROP 列名字;
|
||||
```
|
||||
|
||||
我们把刚才新增的 `test` 删除:
|
||||
|
||||
```sql
|
||||
ALTER TABLE employee DROP test;
|
||||
```
|
||||
|
||||
#### 重命名一列
|
||||
|
||||
这条语句其实不只可用于重命名一列,准确地说,它是对一个列做修改(CHANGE) :
|
||||
|
||||
```sql
|
||||
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;
|
||||
```
|
||||
|
||||
> **注意:这条重命名语句后面的 “数据类型” 不能省略,否则重命名失败。**
|
||||
|
||||
当**原列名**和**新列名**相同的时候,指定新的**数据类型**或**约束**,就可以用于修改数据类型或约束。需要注意的是,修改数据类型可能会导致数据丢失,所以要慎重使用。
|
||||
|
||||
我们用这条语句将 “height” 一列重命名为汉语拼音 “shengao” ,效果如下:
|
||||
|
||||
```mysql
|
||||
ALTER TABLE employee CHANGE height shengao INT(4) DEFAULT 170;
|
||||
```
|
||||
|
||||
#### 改变数据类型
|
||||
|
||||
要修改一列的数据类型,除了使用刚才的 **CHANGE** 语句外,还可以用这样的 **MODIFY** 语句:
|
||||
|
||||
```sql
|
||||
ALTER TABLE 表名字 MODIFY 列名字 新数据类型;
|
||||
```
|
||||
|
||||
再次提醒,修改数据类型必须小心,因为这可能会导致数据丢失。在尝试修改数据类型之前,请慎重考虑。
|
||||
|
||||
#### 修改表中某个值
|
||||
|
||||
大多数时候我们需要做修改的不会是整个数据库或整张表,而是表中的某一个或几个数据,这就需要我们用下面这条命令达到精确的修改:
|
||||
|
||||
```sql
|
||||
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件;
|
||||
```
|
||||
|
||||
比如,我们要把 Tom 的 age 改为 21,salary 改为 3000:
|
||||
|
||||
```mysql
|
||||
UPDATE employee SET age=21,salary=3000 WHERE name='Tom';
|
||||
```
|
||||
|
||||
> **注意:一定要有 WHERE 条件,否则会出现你不想看到的后果**
|
||||
|
||||
#### 删除一行记录
|
||||
|
||||
删除表中的一行数据,也必须加上 WHERE 条件,否则整列的数据都会被删除。删除语句:
|
||||
|
||||
```sql
|
||||
DELETE FROM 表名字 WHERE 条件;
|
||||
```
|
||||
|
||||
我们尝试把 Tom 的数据删除:
|
||||
|
||||
```mysql
|
||||
DELETE FROM employee WHERE name='Tom';
|
||||
```
|
||||
|
||||
#### 索引
|
||||
|
||||
索引是一种与表有关的结构,它的作用相当于书的目录,可以根据目录中的页码快速找到所需的内容。
|
||||
|
||||
当表中有大量记录时,若要对表进行查询,没有索引的情况是全表搜索:将所有记录一一取出,和查询条件进行对比,然后返回满足条件的记录。这样做会执行大量磁盘 I/O 操作,并花费大量数据库系统时间。
|
||||
|
||||
而如果在表中已建立索引,在索引中找到符合查询条件的索引值,通过索引值就可以快速找到表中的数据,可以**大大加快查询速度**。
|
||||
|
||||
对一张表中的某个列建立索引,有以下两种语句格式:
|
||||
|
||||
```sql
|
||||
ALTER TABLE 表名字 ADD INDEX 索引名 (列名);
|
||||
|
||||
CREATE INDEX 索引名 ON 表名字 (列名);
|
||||
```
|
||||
|
||||
我们用这两种语句分别建立索引:
|
||||
|
||||
```sql
|
||||
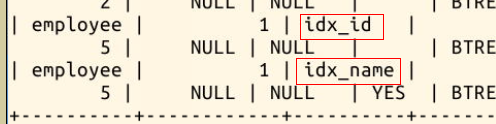
ALTER TABLE employee ADD INDEX idx_id (id); #在employee表的id列上建立名为idx_id的索引
|
||||
|
||||
CREATE INDEX idx_name ON employee (name); #在employee表的name列上建立名为idx_name的索引
|
||||
```
|
||||
|
||||
索引的效果是加快查询速度,当表中数据不够多的时候是感受不出它的效果的。这里我们使用命令 **SHOW INDEX FROM 表名字;** 查看刚才新建的索引:
|
||||
|
||||
|
||||
|
||||
在使用 SELECT 语句查询的时候,语句中 WHERE 里面的条件,会**自动判断有没有可用的索引**。
|
||||
|
||||
比如有一个用户表,它拥有用户名(username)和个人签名(note)两个字段。其中用户名具有唯一性,并且格式具有较强的限制,我们给用户名加上一个唯一索引;个性签名格式多变,而且允许不同用户使用重复的签名,不加任何索引。
|
||||
|
||||
这时候,如果你要查找某一用户,使用语句 `select * from user where username=?` 和 `select * from user where note=?` 性能是有很大差距的,对**建立了索引的用户名**进行条件查询会比**没有索引的个性签名**条件查询快几倍,在数据量大的时候,这个差距只会更大。
|
||||
|
||||
一些字段不适合创建索引,比如性别,这个字段存在大量的重复记录无法享受索引带来的速度加成,甚至会拖累数据库,导致数据冗余和额外的 CPU 开销。
|
||||
|
||||
## 视图
|
||||
|
||||
|
||||
|
||||
视图是从一个或多个表中导出来的表,是一种**虚拟存在的表**。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据。
|
||||
|
||||
注意理解视图是虚拟的表:
|
||||
|
||||
- 数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
|
||||
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
|
||||
- 视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
|
||||
- 在使用视图的时候,可以把它当作一张表。
|
||||
|
||||
创建视图的语句格式为:
|
||||
|
||||
```sql
|
||||
CREATE VIEW 视图名(列a,列b,列c) AS SELECT 列1,列2,列3 FROM 表名字;
|
||||
```
|
||||
|
||||
可见创建视图的语句,后半句是一个 SELECT 查询语句,所以**视图也可以建立在多张表上**,只需在 SELECT 语句中使用**子查询**或**连接查询**,这些在之前的实验已经进行过。
|
||||
|
||||
现在我们创建一个简单的视图,名为 **v_emp**,包含**v_name**,**v_age**,**v_phone**三个列:
|
||||
|
||||
```sql
|
||||
CREATE VIEW v_emp (v_name,v_age,v_phone) AS SELECT name,age,phone FROM employee;
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 导出
|
||||
|
||||
|
||||
|
||||
导出与导入是相反的过程,是把数据库某个表中的数据保存到一个文件之中。导出语句基本格式为:
|
||||
|
||||
```sql
|
||||
SELECT 列1,列2 INTO OUTFILE '文件路径和文件名' FROM 表名字;
|
||||
```
|
||||
|
||||
**注意:语句中 “文件路径” 之下不能已经有同名文件。**
|
||||
|
||||
现在我们把整个 employee 表的数据导出到 /var/lib/mysql-files/ 目录下,导出文件命名为 **out.txt** 具体语句为:
|
||||
|
||||
```sql
|
||||
SELECT * INTO OUTFILE '/var/lib/mysql-files/out.txt' FROM employee;
|
||||
```
|
||||
|
||||
用 gedit 可以查看导出文件 `/var/lib/mysql-files/out.txt` 的内容:
|
||||
|
||||
> 也可以使用 `sudo cat /var/lib/mysql-files/out.txt` 命令查看。
|
||||
|
||||
## 备份
|
||||
|
||||
|
||||
|
||||
数据库中的数据十分重要,出于安全性考虑,在数据库的使用中,应该注意使用备份功能。
|
||||
|
||||
> 备份与导出的区别:导出的文件只是保存数据库中的数据;而备份,则是把数据库的结构,包括数据、约束、索引、视图等全部另存为一个文件。
|
||||
|
||||
**mysqldump** 是 MySQL 用于备份数据库的实用程序。它主要产生一个 SQL 脚本文件,其中包含从头重新创建数据库所必需的命令 CREATE TABLE INSERT 等。
|
||||
|
||||
使用 mysqldump 备份的语句:
|
||||
|
||||
```bash
|
||||
mysqldump -u root 数据库名>备份文件名; #备份整个数据库
|
||||
|
||||
mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表
|
||||
```
|
||||
|
||||
> mysqldump 是一个备份工具,因此该命令是在终端中执行的,而不是在 mysql 交互环境下
|
||||
|
||||
我们尝试备份整个数据库 `mysql_shiyan`,将备份文件命名为 `bak.sql`,先 `Ctrl+D` 退出 MySQL 控制台,再打开 Xfce 终端,在终端中输入命令:
|
||||
|
||||
```bash
|
||||
cd /home/shiyanlou/
|
||||
mysqldump -u root mysql_shiyan > bak.sql;
|
||||
```
|
||||
|
||||
使用命令 “ls” 可见已经生成备份文件 `bak.sql`:
|
||||
|
||||

|
||||
|
||||
> 你可以用 gedit 查看备份文件的内容,可以看见里面不仅保存了数据,还有所备份的数据库的其它信息。
|
||||
|
||||
## 恢复
|
||||
|
||||
|
||||
|
||||
用备份文件恢复数据库,其实我们早就使用过了。在本次实验的开始,我们使用过这样一条命令:
|
||||
|
||||
```bash
|
||||
source /tmp/SQL6/MySQL-06.sql
|
||||
```
|
||||
|
||||
这就是一条恢复语句,它把 MySQL-06.sql 文件中保存的 `mysql_shiyan` 数据库恢复。
|
||||
|
||||
还有另一种方式恢复数据库,但是在这之前我们先使用命令新建一个**空的数据库 test**:
|
||||
|
||||
```bash
|
||||
mysql -u root #因为在上一步已经退出了 MySQL,现在需要重新登录
|
||||
CREATE DATABASE test; #新建一个名为test的数据库
|
||||
```
|
||||
|
||||
再次 **Ctrl+D** 退出 MySQL,然后输入语句进行恢复,把刚才备份的 **bak.sql** 恢复到 **test** 数据库:
|
||||
|
||||
```bash
|
||||
mysql -u root test < bak.sql
|
||||
```
|
||||
|
||||
我们输入命令查看 test 数据库的表,便可验证是否恢复成功:
|
||||
|
||||
```bash
|
||||
mysql -u root # 因为在上一步已经退出了 MySQL,现在需要重新登录
|
||||
use test # 连接数据库 test
|
||||
|
||||
SHOW TABLES; # 查看 test 数据库的表
|
||||
```
|
||||
|
||||
可以看见原数据库的 4 张表和 1 个视图,现在已经恢复到 test 数据库中:
|
||||
|
||||

|
||||
|
||||
再查看 employee 表的恢复情况:
|
||||
|
||||
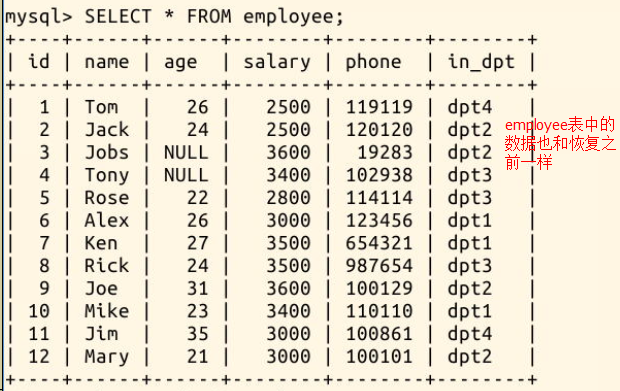
|
||||
|
||||
## Mysql授权
|
||||
|
||||
1. 登录MySQL:
|
||||
|
||||
```sql
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
2. 进入MySQL并查看用户和主机:
|
||||
|
||||
```sql
|
||||
use mysql;
|
||||
select host,user from user;
|
||||
```
|
||||
|
||||
3. 更新root用户允许远程连接:
|
||||
|
||||
```sql
|
||||
update user set host='%' where user='root';
|
||||
```
|
||||
|
||||
4. 设置root用户密码:
|
||||
|
||||
```sql
|
||||
alter user 'root'@'localhost' identified by 'your_password';
|
||||
```
|
||||
|
||||
注意:不要使用临时密码。
|
||||
|
||||
5. 授权允许远程访问:
|
||||
|
||||
```sql
|
||||
grant all privileges on *.* to 'root'@'%' identified by 'password';
|
||||
```
|
||||
|
||||
请将命令中的“password”更改为您的MySQL密码。
|
||||
|
||||
6. 刷新授权:
|
||||
|
||||
```sql
|
||||
flush privileges;
|
||||
```
|
||||
|
||||
7. 关闭授权:
|
||||
|
||||
```sql
|
||||
revoke all on *.* from dba@localhost;
|
||||
```
|
||||
|
||||
8. 查看MySQL初始密码:
|
||||
|
||||
```bash
|
||||
grep "password" /var/log/mysqld.log
|
||||
```
|
||||
|
||||
通过以上操作,您的MySQL可以被远程连接并进行管理。请注意在授权和更新用户权限时,应只授权特定的数据库或表格,而不是使用通配符,以提高安全性和减少不必要的权限。在进行远程访问授权时,应只授权特定的IP地址或IP地址段,而不是使用通配符,以减少潜在的安全威胁。同时,建议使用强密码,并定期更换密码以提高安全性。
|
||||
@@ -1,119 +0,0 @@
|
||||
---
|
||||
title: "Redis 安装与常用命令整理"
|
||||
slug: redis
|
||||
description: "文章介绍了 Redis 在 Debian 下的安装方法、Windows 图形客户端的安装方式,以及监听端口修改、BitMap、消息队列、LREM 和 Pipeline 等常用操作示例。"
|
||||
category: "数据库"
|
||||
post_type: "article"
|
||||
pinned: false
|
||||
published: true
|
||||
tags:
|
||||
- "Redis安装"
|
||||
- "Debian"
|
||||
- "BitMap"
|
||||
- "消息队列"
|
||||
- "Pipeline"
|
||||
- "go-redis"
|
||||
---
|
||||
|
||||
# 安装`Redis`
|
||||
|
||||
## `Debian`下安装`Redis`服务端
|
||||
|
||||
```bash
|
||||
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
|
||||
|
||||
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install redis
|
||||
```
|
||||
|
||||
## `Windows`下安装`Redis` 第三方`GUI`客户端
|
||||
|
||||
Redis (GUI)管理客户端
|
||||
|
||||
```bash
|
||||
winget install qishibo.AnotherRedisDesktopManager
|
||||
```
|
||||
|
||||
## `Redis`修改监听端口
|
||||
|
||||
```bash
|
||||
vim /etc/redis/redis.conf
|
||||
```
|
||||
|
||||
# `Redis`常用命令
|
||||
|
||||
## `bitMap`
|
||||
|
||||
使用`BitMap`实现签到,`setbit key offset value,` `key`做为时间,`offset`做为用户`id` ,`value`做为签到状态
|
||||
|
||||
```shell
|
||||
# 示例
|
||||
setbit key offset value key
|
||||
# 设置用户10086在2022/04/21进行签到
|
||||
setbit check_in_2022_04_21 10086 1
|
||||
# 获取用户10086是否在2022/04/21签到
|
||||
getbit check_in_2022_04_21 10086
|
||||
# bitcount 获取20220421签到的用户数量
|
||||
# 可选 start和end参数
|
||||
# start 和 end 参数的设置和 GETRANGE 命令类似,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位
|
||||
BITCOUNT 20220421
|
||||
# BITOP 对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上
|
||||
|
||||
# operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种:
|
||||
|
||||
# BITOP AND destkey key [key ...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。
|
||||
|
||||
# BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey 。
|
||||
|
||||
# BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。
|
||||
|
||||
# BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey 。
|
||||
|
||||
# 除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入。
|
||||
|
||||
BITOP AND and-result 20220421 20220420
|
||||
GETBIT and-result
|
||||
|
||||
```
|
||||
|
||||
## `Redis` 消息队列
|
||||
|
||||
```
|
||||
# LPUSH key value, Lpush用于生产并添加消息
|
||||
# LPOP key,用于取出消息
|
||||
```
|
||||
|
||||
## `Lrem`
|
||||
|
||||
```shell
|
||||
# count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
|
||||
# count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
|
||||
# count = 0 : 移除表中所有与 VALUE 相等的值。
|
||||
LREM key count VALUE
|
||||
```
|
||||
|
||||
## `Pipeline`
|
||||
|
||||
`Redis` 使用的是客户端-服务器(`CS`)模型和请求/响应协议的 TCP 服务器。这意味着通常情况下一个请求会遵循以下步骤:
|
||||
|
||||
客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
|
||||
服务端处理命令,并将结果返回给客户端。
|
||||
管道(`pipeline`)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 `Pipeline` 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。
|
||||
|
||||
通俗点:`pipeline`就是把一组命令进行打包,然后一次性通过网络发送到Redis。同时将执行的结果批量的返回回来
|
||||
|
||||
```go
|
||||
// 使用 go-redis
|
||||
p := Client.Pipeline()
|
||||
for _, v := range val {
|
||||
p.LRem("user:watched:"+guid, 0, v)
|
||||
}
|
||||
// p.Exec()执行pipeline 请求
|
||||
p.Exec()
|
||||
```
|
||||
|
||||
|
||||
|
||||
[本文参考](https://blog.csdn.net/mumuwang1234/article/details/118603697)
|
||||
@@ -1,169 +0,0 @@
|
||||
---
|
||||
title: "手把手教你用Rust进行Dll注入"
|
||||
description: 我是一个懒惰的男孩,我甚至懒的不想按键盘上的按键和挪动鼠标.可是我还是想玩游戏,该怎么做呢?通过 google 了解到我可以通过将我自己编写的dll文件注入到目标程序内,来实现这个事情.
|
||||
date: 2022-09-17T15:10:26+08:00
|
||||
draft: false
|
||||
slug: rust-dll
|
||||
image:
|
||||
categories:
|
||||
- Rust
|
||||
tags:
|
||||
- Rust
|
||||
- Dll
|
||||
---
|
||||
|
||||
# 前言
|
||||
|
||||
我是一个懒惰的男孩,我甚至懒的不想按键盘上的按键和挪动鼠标.可是我还是想玩游戏,该怎么做呢?
|
||||
|
||||
通过google了解到我可以通过将我自己编写的 `dll` 文件注入到目标程序内,来实现这个事情.
|
||||
|
||||
将大象放在冰箱里需要几步?
|
||||
|
||||
答案是三步。
|
||||
|
||||
# `snes9x` 模拟器 `Dll` 注入实战
|
||||
|
||||
## 一、现在我们需要进行第一步,生成 `Dll` 文件
|
||||
|
||||
准确说是我们需要生成符合 `C` 标准的 `dll` 文件,如果你使用 `go` 语言,直接使用 `Cgo` 与 `C` 进行互动,即可生成符合 `C` 标准的 `dll` .
|
||||
|
||||
但是很明显,我要用 `Rust` 来做这件事。
|
||||
|
||||
由于 `Rust` 拥有出色的所有权机制,和其他语言的交互会导致 `Rust` 失去这个特性,所以这一块是属于 `Unsafe` 区域的。
|
||||
|
||||
`Rust` 默认生成的 `Dll` 是提供给 `Rust` 语言来调用的,而非C系语言的 `dll`.
|
||||
|
||||
我们现在来生成 `C` 系语言的 `Dll` 吧。
|
||||
|
||||
### 1.新建项目 `lib` 目录 `lib` 目录主要作为库文件以方便其他开发者调用
|
||||
|
||||
```bash
|
||||
# 新建库项目
|
||||
Cargo new --lib <project name>
|
||||
Cargo new --lib joy
|
||||
```
|
||||
|
||||
### 2.修改 `Cargo.toml` 文件 增加 `bin` 区域
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "joy"
|
||||
version = "0.1.0"
|
||||
edition = "2021"
|
||||
|
||||
[lib]
|
||||
name = "joy"
|
||||
path = "src/lib.rs"
|
||||
crate-type = ["cdylib"]
|
||||
|
||||
[[bin]]
|
||||
name = "joyrun"
|
||||
path = "src/main.rs"
|
||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
```
|
||||
|
||||
```bash
|
||||
# 为项目导入依赖ctor来生成符合c标准的dll
|
||||
cargo add ctor
|
||||
```
|
||||
|
||||
### 3.修改 `lib.rs` 使用 `ctor`
|
||||
|
||||
```rust
|
||||
// lib.rs
|
||||
#[ctor::ctor]
|
||||
fn ctor() {
|
||||
println!("我是一个dll")
|
||||
}
|
||||
```
|
||||
|
||||
#### 4.编译项目生成 `joy.dll` 以及 `joyrun.exe`
|
||||
|
||||
```bash
|
||||
cargo build
|
||||
```
|
||||
|
||||
现在我们有了我们自己的 `dll` 文件,该如何将他注入到目标的进程呢?
|
||||
|
||||
## 二、使用 `dll-syringe` 进行dll注入
|
||||
|
||||
```
|
||||
cargo add dll-syringe
|
||||
```
|
||||
|
||||
### 1.修改main.rs 将刚刚编写的dll注入到目标应用
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
use dll_syringe::{Syringe, process::OwnedProcess};
|
||||
|
||||
fn main() {
|
||||
// 通过进程名找到目标进程
|
||||
let target_process = OwnedProcess::find_first_by_name("snes9x").unwrap();
|
||||
|
||||
// 新建一个注入器
|
||||
let syringe = Syringe::for_process(target_process);
|
||||
|
||||
// 将我们刚刚编写的dll加载进去
|
||||
let injected_payload = syringe.inject("joy.dll").unwrap();
|
||||
|
||||
// do something else
|
||||
|
||||
// 将我们刚刚注入的dll从目标程序内移除
|
||||
syringe.eject(injected_payload).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
### 2.运行项目
|
||||
|
||||
```shell
|
||||
# 运行项目
|
||||
cargo run
|
||||
```
|
||||
|
||||
此时你可能会遇到一个新问题,我的`dll`已经加载进目标程序了,为什么没有打印 "我是一个dll"
|
||||
|
||||
### 3.解决控制台无输出问题
|
||||
|
||||
这是由于目标程序没有控制台,所以我们没有看到 `dll` 的输出,接下来让我们来获取 `dll` 的输出。
|
||||
|
||||
此时我们可以使用 `TCP` 交互的方式或采用 `OutputDebugStringA function (debugapi.h)` 来进行打印
|
||||
|
||||
`OutputDebugStringA` ,需要额外开启`features` `Win32_System_Diagnostics_Debug`
|
||||
|
||||
```rust
|
||||
// Rust Unsafe fn
|
||||
// windows::Win32::System::Diagnostics::Debug::OutputDebugStringA
|
||||
pub unsafe fn OutputDebugStringA<'a, P0>(lpoutputstring: P0)
|
||||
where
|
||||
P0: Into<PCSTR>,
|
||||
// Required features: "Win32_System_Diagnostics_Debug"
|
||||
```
|
||||
|
||||
采用 `Tcp` 通信交互
|
||||
|
||||
```rust
|
||||
// 在lib.rs 新建tcp客户端
|
||||
let stream = TcpStream::connect("127.0.0.1:7331").unwrap();
|
||||
```
|
||||
|
||||
```rust
|
||||
// 在main.rs 新建tcp服务端
|
||||
let (mut stream, addr) = listener.accept()?;
|
||||
info!(%addr,"Accepted!");
|
||||
let mut buf = vec![0u8; 1024];
|
||||
let mut stdout = std::io::stdout();
|
||||
while let Ok(n) = stream.read(&mut buf[..]) {
|
||||
if n == 0 {
|
||||
break;
|
||||
}
|
||||
stdout.write_all(&buf[..n])?
|
||||
}
|
||||
```
|
||||
|
||||
```shell
|
||||
# 运行项目
|
||||
cargo run
|
||||
# 运行之后,大功告成,成功在Tcp服务端看到了,客户端对我们发起了请求。
|
||||
```
|
||||
24
backend/content/posts/rust-programming-tips.md
Normal file
24
backend/content/posts/rust-programming-tips.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 徐霞客游记·游恒山日记
|
||||
slug: rust-programming-tips
|
||||
description: 游恒山、悬空寺与北岳登顶的古文纪行,适合做中文长文测试。
|
||||
category: 古籍游记
|
||||
post_type: article
|
||||
pinned: false
|
||||
status: published
|
||||
visibility: public
|
||||
noindex: false
|
||||
tags:
|
||||
- 徐霞客
|
||||
- 恒山
|
||||
- 悬空寺
|
||||
- 长文测试
|
||||
---
|
||||
|
||||
# 徐霞客游记·游恒山日记
|
||||
|
||||
出南山。大溪从山中俱来者,别而西去。余北驰平陆中,望外界之山,高不及台山十之四,其长缭绕如垣。
|
||||
|
||||
余溯西涧入,又一涧自北来,遂从其西登岭,道甚峻。北向直上者六七里,西转,又北跻而上者五六里,登峰两重,造其巅,是名箭筸岭。
|
||||
|
||||
三转,峡愈隘,崖愈高。西崖之半,层楼高悬,曲榭斜倚,望之如蜃吐重台者,悬空寺也。
|
||||
@@ -1,96 +0,0 @@
|
||||
---
|
||||
title: "Rust使用Serde进行序列化及反序列化"
|
||||
description: 这篇文章将介绍如何在Rust编程语言中使用Serde库进行序列化和反序列化操作。Serde是一个广泛使用的序列化和反序列化库,能够支持JSON、BSON、CBOR、MessagePack和YAML等常见数据格式。
|
||||
date: 2022-07-25T14:02:22+08:00
|
||||
draft: false
|
||||
slug: rust-serde
|
||||
image:
|
||||
categories:
|
||||
- Rust
|
||||
tags:
|
||||
- Rust
|
||||
- Xml
|
||||
---
|
||||
|
||||
# 开始之前
|
||||
|
||||
```toml
|
||||
# 在Cargo.toml 新增以下依赖
|
||||
[dependencies]
|
||||
serde = { version = "1.0.140",features = ["derive"] }
|
||||
serde_json = "1.0.82"
|
||||
serde_yaml = "0.8"
|
||||
serde_urlencoded = "0.7.1"
|
||||
# 使用yaserde解析xml
|
||||
yaserde = "0.8.0"
|
||||
yaserde_derive = "0.8.0"
|
||||
```
|
||||
|
||||
## `Serde`通用规则(`json`,`yaml`,`xml`)
|
||||
|
||||
### 1.使用`Serde`宏通过具体结构实现序列化及反序列化
|
||||
|
||||
```rust
|
||||
use serde::{Deserialize, Serialize};
|
||||
// 为结构体实现 Serialize(序列化)属性和Deserialize(反序列化)
|
||||
#[derive(Debug, Serialize, Deserialize, Clone)]
|
||||
pub struct Person {
|
||||
// 将该字段名称修改为lastname
|
||||
#[serde(rename = "lastname")]
|
||||
name: String,
|
||||
// 反序列化及序列化时忽略该字段(nickname)
|
||||
#[serde(skip)]
|
||||
nickname: String,
|
||||
// 分别设置序列化及反序列化时输出的字段名称
|
||||
#[serde(rename(serialize = "serialize_id", deserialize = "derialize_id"))
|
||||
id: i32,
|
||||
// 为age设置默认值
|
||||
#[serde(default)]
|
||||
age: i32,
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### 2.使用`serde_json`序列化及反序列化
|
||||
|
||||
```rust
|
||||
use serde_json::{json, Value};
|
||||
let v:serde_json::Value = json!(
|
||||
{
|
||||
"x":20.0,
|
||||
"y":15.0
|
||||
}
|
||||
);
|
||||
println!("x:{:#?},y:{:#?}",v["x"],v["y"]); // x:20.0, y:15.0
|
||||
```
|
||||
|
||||
### 3.使用`Serde`宏统一格式化输入、输出字段名称
|
||||
|
||||
| 方法名 | 方法效果 |
|
||||
| ------------------------------- | ------------------------------------------------------------ |
|
||||
| `PascalCase` | 首字母为大写的驼峰式命名,推荐结构体、枚举等名称以及`Yaml`配置文件读取使用。 |
|
||||
| `camelCase` | 首字母为小写的驼峰式命名,推荐`Yaml`配置文件读取使用。 |
|
||||
| `snake_case` | 小蛇形命名,用下划线"`_`"连接单词,推荐函数命名以及变量名称使用此种方式。 |
|
||||
| `SCREAMING_SNAKE_CASE` | 大蛇形命名,单词均为大写形式,用下划线"`_`"连接单词。推荐常数及全局变量使用此种方式。 |
|
||||
| `kebab-case`(小串烤肉) | 同`snake_case`,使用中横线"`-`"替换了下划线"`_`"。 |
|
||||
| `SCREAMING-KEBAB-CAS`(大串烤肉) | 同`SCREAMING_SNAKE_CASE`,使用中横线"`-`"替换了下划线"`_`"。 |
|
||||
|
||||
示例:
|
||||
|
||||
```rust
|
||||
pub struct App {
|
||||
#[serde(rename_all = "PascalCase")]
|
||||
/// 统一格式化输入、输出字段名称
|
||||
/// #[serde(rename_all = "camelCase")]
|
||||
/// #[serde(rename_all = "snake_case")]
|
||||
/// #[serde(rename_all = "SCREAMING_SNAKE_CASE")]
|
||||
/// 仅设置
|
||||
version: String,
|
||||
app_name: String,
|
||||
host: String,
|
||||
}
|
||||
```
|
||||
|
||||
[本文参考:yaserde](https://github.com/media-io/yaserde)
|
||||
|
||||
[本文参考:magiclen](https://magiclen.org/rust-serde/)
|
||||
@@ -1,37 +0,0 @@
|
||||
---
|
||||
title: "Rust Sqlx"
|
||||
description:
|
||||
date: 2022-08-29T13:55:08+08:00
|
||||
draft: true
|
||||
slug: rust-sqlx
|
||||
image:
|
||||
categories:
|
||||
-
|
||||
tags:
|
||||
-
|
||||
---
|
||||
|
||||
# sqlx-cli
|
||||
|
||||
## 创建 migration
|
||||
|
||||
```shell
|
||||
sqlx migrate add categories
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Add migration script here
|
||||
CREATE TABLE IF NOT EXISTS categories(
|
||||
id INT PRIMARY KEY DEFAULT AUTO_INCREMENT,
|
||||
type_id INT UNIQUE NOT NULL,
|
||||
parent_id INT NOT NULL,
|
||||
name TEXT UNIQUE NOT NULL,
|
||||
);
|
||||
```
|
||||
|
||||
## 运行 migration
|
||||
|
||||
```sh
|
||||
sqlx migrate run
|
||||
```
|
||||
|
||||
24
backend/content/posts/terminal-ui-design.md
Normal file
24
backend/content/posts/terminal-ui-design.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 游黄山记(上)
|
||||
slug: terminal-ui-design
|
||||
description: 钱谦益《游黄山记》上篇,包含序、记之一与记之二。
|
||||
category: 古籍游记
|
||||
post_type: article
|
||||
pinned: false
|
||||
status: published
|
||||
visibility: public
|
||||
noindex: false
|
||||
tags:
|
||||
- 钱谦益
|
||||
- 黄山
|
||||
- 游记
|
||||
- 长文测试
|
||||
---
|
||||
|
||||
# 游黄山记(上)
|
||||
|
||||
辛巳春,余与程孟阳订黄山之游,约以梅花时相寻于武林之西溪。徐维翰书来劝驾,读之两腋欲举,遂挟吴去尘以行。
|
||||
|
||||
黄山耸秀峻极,作镇一方。江南诸山,天台、天目为最,以地形准之,黄山之趾与二山齐。
|
||||
|
||||
自山口至汤口,山之麓也,登山之径于是始。汤泉之流,自紫石峰六百仞县布,其下有香泉溪。
|
||||
@@ -1,54 +0,0 @@
|
||||
---
|
||||
title: "在 Tmux 会话窗格中发送命令的方法"
|
||||
slug: tmux
|
||||
description: "介绍如何在 Tmux 中创建分离会话、向指定窗格发送命令并执行回车,同时说明连接会话和发送特殊按键的基本用法。"
|
||||
category: "Linux"
|
||||
post_type: "article"
|
||||
pinned: false
|
||||
published: true
|
||||
tags:
|
||||
- "Tmux"
|
||||
- "终端复用"
|
||||
- "send-keys"
|
||||
- "会话管理"
|
||||
- "命令行"
|
||||
---
|
||||
|
||||
## 在 Tmux 会话窗格中发送命令的方法
|
||||
|
||||
在 `Tmux` 中,可以使用 `send-keys` 命令将命令发送到会话窗格中。以下是在 `Tmux` 中发送命令的步骤:
|
||||
|
||||
### 1. 新建一个分离(`Detached`)会话
|
||||
|
||||
使用以下命令新建一个分离会话:
|
||||
|
||||
```bash
|
||||
tmux new -d -s mySession
|
||||
```
|
||||
|
||||
### 2. 发送命令至会话窗格
|
||||
|
||||
使用以下命令将命令发送到会话窗格:
|
||||
|
||||
```bash
|
||||
tmux send-keys -t mySession "echo 'Hello World!'" ENTER
|
||||
```
|
||||
|
||||
这将发送 `echo 'Hello World!'` 命令,并模拟按下回车键(`ENTER`),以在会话窗格中执行该命令。
|
||||
|
||||
### 3. 连接(`Attach`)会话窗格
|
||||
|
||||
使用以下命令连接会话窗格:
|
||||
|
||||
```bash
|
||||
tmux a -t mySession
|
||||
```
|
||||
|
||||
这将连接到名为 `mySession` 的会话窗格。
|
||||
|
||||
### 4. 发送特殊命令
|
||||
|
||||
要发送特殊命令,例如清除当前行或使用管理员权限运行命令,请使用以下命令:
|
||||
|
||||
- 清除当前行:`tmux send-keys C-c`
|
||||
- 以管理员身份运行命令:`sudo tmux send-keys ...`
|
||||
24
backend/content/posts/welcome-to-termi.md
Normal file
24
backend/content/posts/welcome-to-termi.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 徐霞客游记·游太和山日记(上)
|
||||
slug: welcome-to-termi
|
||||
description: 《徐霞客游记》太和山上篇,适合作为中文长文测试样本。
|
||||
category: 古籍游记
|
||||
post_type: article
|
||||
pinned: true
|
||||
status: published
|
||||
visibility: public
|
||||
noindex: false
|
||||
tags:
|
||||
- 徐霞客
|
||||
- 游记
|
||||
- 太和山
|
||||
- 长文测试
|
||||
---
|
||||
|
||||
# 徐霞客游记·游太和山日记(上)
|
||||
|
||||
登仙猿岭。十馀里,有枯溪小桥,为郧县境,乃河南、湖广界。东五里,有池一泓,曰青泉,上源不见所自来,而下流淙淙,地又属淅川。
|
||||
|
||||
自此连逾山岭,桃李缤纷,山花夹道,幽艳异常。山坞之中,居庐相望,沿流稻畦,高下鳞次,不似山、陕间矣。
|
||||
|
||||
骑而南趋,石道平敞。三十里,越一石梁,有溪自西东注,即太和下流入汉者。越桥为迎恩宫,西向。前有碑大书“第一山”三字,乃米襄阳笔。
|
||||
Reference in New Issue
Block a user